パイプを使った通信にはいくつか制限があります。まず、パイプを使うとローカルのマシンとしか通信できません。名前付きパイプではやり取りをするプロセスが同じマシンで実行される必要があり、名前無しパイプでは二つのプロセスは親子関係になくてはいけません。次に、パイプでは クライアント-サーバ モデルという便利な通信モデルを使うことが難しいです。このモデルではちょうど一つの サーバ プログラムだけが共有リソースにアクセスできます。そして他の クライアント はサーバにアクセスすることで共有リソースにアクセスします。サーバが共有リソースへのアクセスの制御と管理を行うということです。例えば x-window システムでは共有リソースとはスクリーンとキーボード、そしてマウスです。
クライアント-サーバモデルをパイプで実装するのは難しいです。一番の困難はクライアントとサーバの間の接続を確立する部分です。名前無しパイプではこれは不可能です。サーバとクライアントに共通の親が必要であり、その親は任意の数のパイプを前もって保持する必要があるからです。名前付きパイプを使えばサーバがクライアントからの接続を読むことは不可能ではありません。しかしこの場合サーバが受け取るリクエストにはクライアントがサーバとやり取りするのに使う他の名前付きパイプの名前も含まれるので、複数のクライアントからの接続リクエストをどう排他制御するかが問題となります。
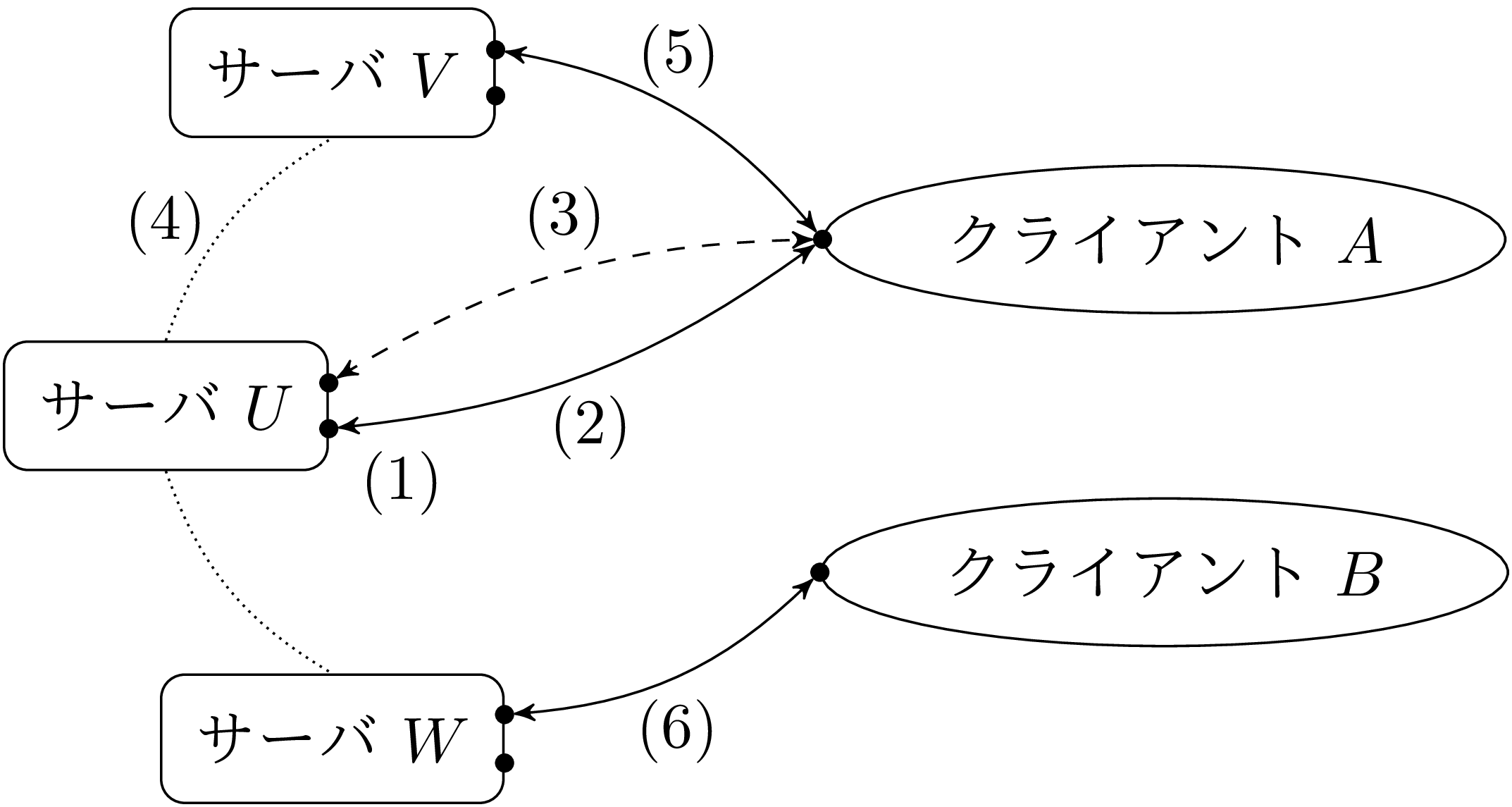
ソケットはこれらの問題を解決するために一般化されたパイプです。ソケットの説明のために、まずクライアント-サーバモデルを図 3 に示します。
上記のモデルでは、サーバ U とクライアント A はプライベートな接続 (3) を確立することで他のクライアントの影響を受けずにやり取りを行います。このことから、この通信方式は コネクション型通信 と呼ばれます。通信が短ければサーバが (フォークせずに) 直接リクエストを処理することもできます。しかしこうするとサーバが接続 (3) を処理するのを待つため、あるいは複数の接続が多重化によって管理されているために、クライアントはサーバが利用可能になるまで待たなければいけません。
ソケットを使うと コネクションレス型通信 を利用することもできます。この方式ではサーバはクライアントとプライベートな接続を確立することなく直接通信します。コネクション型通信と比べるとこの方式が使われることは少ないです。 6.10 節で少しコメントしますが、この章では主にコネクション型通信を扱います。
ソケットはパイプの拡張であり、bsd 4.2 で初めて実装されました。現在ではネットワークに接続するすべての Unix がソケットの機能を持ちます。クライアント-サーバモデルに沿った通信を行うための専用のシステムコールが存在します。このシステムコールによって、プロセス間のローカル通信およびリモート通信を (ほぼ) 透過的に行うことができます。
ソケットの 通信ドメイン は通信できるプロセス (およびそのアドレスのフォーマット) を制限します。異なる通信ドメインが利用可能です。例えば:
129.199.129.1 のような形をしたもの) とマシンのポート番号。通信はインターネットに接続している任意の二つのマシンで実行されるプロセス間で可能1。
ソケットの 通信方式 は通信が信頼できるか (データの消失や重複があるか)、そしてデータの送受信の方法 (バイトストリーム、パケット列 — バイトの小さなブロック) を示します。通信方式はデータの送受信に使われるプロトコルを規定します。いくつかの通信方式が利用可能です。三つの通信方式をその特徴と共に示します:
| 方式 | 信頼性 | データ表現 |
| ストリーム | 信頼できる | バイトストリーム |
| データグラム | 信頼できない | パケット |
| セグメント化されたパケット | 信頼できる | パケット |
“ストリーム” 方式はパイプを使った通信にとても良く似ており、一番良く使われます。例えば構造化されていないバイトシーケンスの転送 (例えば rsh) などに使われます。“セグメント化されたパケット” 方式はデータをパケットとして転送します。すべての書き込みはパケットごとに区切られ、すべての読み込みは多くとも一つのパケットしか読み込めません。この方式はメッセージ指向の通信に適しています。“データグラム” 方式はイーサネットネットワークのハードウェアの特徴に一番近いです。データはパケットで転送されますが、それぞれのパッケットが目的地に届く保証はありません。ネットワークのリソースという観点では、この方式が一番無駄が少ないです。この方式は致命的な重要性を持たないデータの転送を行うプログラム (例えば biff) によって使われます。またデータの消失を手動で管理することでネットワークのパフォーマンスを向上させることもできます。
システムコール socket は新しいソケットを作成します:
返り値は新しいソケットを表すファイルディスクリプタです。初期状態ではこのディスクリプタは “切断” 状態であり、 read や write を受け付ける準備が整っていません。
第一引数は socket_domain 型の値で、通信ドメインを指定します:
PF_UNIX | ユニックスドメイン |
PF_INET | インターネットドメイン |
第二引数は socket_type 型の値で、通信方式を指定します:
SOCK_STREAM | 信頼できるバイトストリーム |
SOCK_DGRAM | 信頼できないパケット |
SOCK_RAW | ネットワークの下層への直接のアクセス |
SOCK_SEQPACKET | 信頼できるパケット |
第三引数は通信で使うプロトコルです。通信ドメインに対するデフォルトのプロトコル (例えば SOCK_DGRAM に対しては udp、SOCK_STREAM に対しては tcp など) を選択する 0 が通常使われます。第三引数に他の値を設定すると特殊なプロトコルを使うことができます。例えば ping コマンドは icmp (Internet Control Message Protocol) を使って、自動的に送信者に送り返すパケットを送ります。特殊なプロトコルに対する引数の値は /etc/protocols ファイルまたは nis (Network Information Service) データベース の protocols テーブルが存在すればそこにあります。システムコール getprotobyname はプロトコルに関する情報をポータブルな形で返します。
引数はプロトコルの名前で、返り値は protocol_entry 型のレコードです。このレコードの p_proto フィールドがプロトコルの番号を表します。
ソケットに関する操作はソケットアドレスを利用するものがあります。ソケットアドレスはヴァリアント型 sockaddr によって表されます:
ADDR_UNIX f は Unix ドメインにおけるアドレスです。 f は対応するファイルのマシンのファイルシステムにおける名前です。 ADDR_INET (a,p) はインターネットドメインにおけるアドレスです。 a がマシンのインターネットアドレスで、p がそのマシンのポート番号です。
インターネットアドレスは抽象型 inet_addr を表します。次の二つの関数は 128.93.8.2 のような形をした文字列と inet_addr 型の値の間の変換を行います。
インターネットアドレスを調べるもう一つの方法はホストの名前を使って /etc/hosts にあるテーブル、nis データベース、あるいはドメインネームサーバから引くことです。システムコール gethostbyname がこれを行います。現代的なマシンではドメインネームサーバへの問い合わせが最初に行われ、/etc/hosts はフォールバックとしてしか使われませんが、一般的にはこの順番はマシンの設定によります。
引数はホストの名前で、返り値は host_entry 型のレコードです。このレコードの h_addr_list フィールドが目的のマシンのインターネットアドレスを表します (同じマシンが複数のネットワークに違うアドレスで接続することは可能です)。
最もよく使われるサービスが使うポート番号は /etc/services のテーブルにリストされており、getservbyname 関数でポ−タブルに取得できます。
第一引数はサービスの名前 (ftp サーバには "ftp"、E メールには "smtp"、ニュースサーバには "nntp"、talk と ntalk にはコマンドと同じ文字列、など) です。第二引数はプロトコルの名前です。プロトコルの名前にはサービスの通信方式がストリーム方式の場合は "tcp" が、データグラム方式の場合は"udp" が通常使われます。getservbyname の返り値は service_entry 型の値で、s_port フィールドがサービスが用いるポート番号を表します。
pauillac.inria.fr の ftp サーバのアドレスを入手するには以下のようにします:
システムコール connect はソケットに関連づいたサーバとの通信を確立します。
第一引数はソケットのディスクリプタで、第二引数はサーバのアドレスです。
接続が確立されると、ソケットのディスクリプタに対する write はサーバにデータを送信し、read はサーバからのデータを受信します。ソケットは入出力の操作に対してパイプのように振る舞います。まず、 read はデータが利用可能でない場合にはブロックし、要求よりも少ないバイト数を返すことがあります。次に、サーバが接続を閉じると read は 0 を返し、 write は読んだプロセスに sigpipe シグナルを送ります。
connect 関数はソケットをシステムによって選ばれたローカルアドレスにバインドします。このアドレスを手動で選んだほうが良い場合もあります。そのような場合は connect 関数を呼ぶ前に bind 関数 (6.7 節を参照) を呼ぶことでアドレスを選ぶことができます。
Unix コマンド netstat は現在のマシン上の接続と状況をリストします。
ソケットを切断する方法は二つあります。最初の方法はソケット close を呼んで入出力用の接続が閉じることです。しかしこれでは大雑把すぎることがあります。例えばファイルの終端を伝えるためにクライアントからサーバの接続を閉じつつもサーバからのデータを受け取るために反対側の接続は保ちたい場合があります。システムコール shutdown を使うと接続の一部を切断できます。
第一引数は閉じるソケットのディスクリプタで、第二引数は shutdown_command 型の値で、どちらの方向の節毒を閉じるのかを指定します。
SHUTDOWN_RECEIVE | 読み込み用のソケットを閉じる。接続のもう一端における write は sigpipe シグナルを呼び出しプロセスに送るようになる。 |
SHUTDOWN_SEND | 書き込み用のソケットを閉じる。接続のもう一端における read はEOF を返すようになる。 |
SHUTDOWN_ALL | 読み込みと書き込み用のソケットを両方閉じる。close と違い、閉じられたソケットのディスクリプタは開放されない。
|
ソケットの切断には close と shutdown のどちらを使っても多少の時間がかかることがあることに注意してください。
client host port が host マシンの port ポートへの接続を確立するような clientコマンドを作成します。さらにこのコマンドは標準入力からのデータを作成したソケットから送信し、受信したデータを標準出力へ書き込みます。例えば、以下のコマンド
は pauillac.inria.fr の 80 版ポートに接続し、ウェブページ /~remy/ に対する http リクエストを送ります。
client が行うのはクライアントとの接続を確立する部分だけであり、特定のプロトコルの実装は client を呼んだプログラムに任されます。この意味で、 client コマンドは “ユニバーサルな” クライアントアプリケーションです。
ライブラリ関数 Misc.retransmit fdin fdout はディスクリプタ fdin から読んだデータを fdout に書き込みます。入力ディスクリプタの終端に達するとディスクリプタを閉じずに関数は終了します。retransmit はシグナルで中断されることがあることに注意してください。
本当の問題はここからです。
接続するインターネットアドレスを決めることから処理が始まります。アドレスはホストネームまたは数字の形を使うことができます。gethostbyname がどちらの場合にも対応しているためです。それからインターネットドメインでストリームタイプのソケットをデフォルトプロトコルで作成し、決定したアドレスのマシンに接続します。
プロセスは fork を使ってクローンします。子プロセスは標準入力からのデータをソケットにコピーします。標準入力の終端に達すると、子プロセスは送信方向の接続を閉じて終了します。親プロセスはソケットから呼んだデータを標準出力にコピーします。ファイルの終端に達すると標準出力を閉じ、子プロセスの終了を待ってから終了します。
このプログラムにおいて、接続が切れる原因は以下の三つです:
write を実行したときに sigpipe シグナルを受け取って終了する。接続が切れたことは呼び出し側に報告されないが、もし必要ならば以下のコードを 19 行目の後に入れることで sigpipe を無視することができる。
これによって代わりに EPIPE エラーが出るようになる。
前の節でクライアントがサーバに接続する方法を見たので、今度はサーバーがクライアントにサービスを提供する方法について見ていきます。まずソケットに特定のアドレスを関連付けネットワークから到達可能にします。システムコール bind がこれを行います。
第一引数はソケットのディスクリプタで、第二引数はバインドするアドレスです。インターネットアドレスとして定数 inet_addr_any を使うと、マシンが持つすべてのインターネットアドレス (複数のサブネットワーク内におけるアドレス) をバインドすることができます。
システムコール listen を使ってソケットが接続を受け入れられる状態にします:
第一引数はソケットのディスクリプタで、第二引数はサーバーがビジー状態のときに保持できるリクエストの数です(数十から大きなサーバーでは数百程度になります) 。接続を待っているクライアントが第二引数で指定した値よりも大きくなった場合、それ以降の接続リクエストは失敗します。
最後に、ソケットのディスクリプタに対するへの接続リクエストはシステムコール accept を通じて受け入れられます。
accept の呼び出しが返った場合、引数として与えられたソケットは影響を受けないので続けて接続リクエストを受け入れることができます。返り値の第一要素はクライアントに接続した新しいディスクリプタです。サーバがこのディスクリプタに書き込んだデータは、クライアントが connect に渡したディスクリプタから読み込むことができます。またクライアントが connect に渡したディスクリプタに書き込んだデータは、accept の返り値の第一要素のディスクリプタから読み込むことができます。
accept の返り値の第一要素はクライアントのアドレスです。接続したクライアントが接続する権限を持っているかを確認したり (例えば x サーバはこの処理を行います。 xhost で新しい許可されたユーザを追加できます)、サーバーからクライアントへの二つめの接続を作成する (ftp はすべてのファイル転送リクエストに対してこの処理を行います) ことに使うことができます。
tcp サーバの一般的な構造は以下のようになっています:
ライブラリ関数 Misc.install_tcp_server addr は bind と listen を使ってストリームタイプでインターネットドメインのソケットをデフォルトプロトコルで作成し、アドレス addr からの接続を受けられるように準備します。この関数はライブラリ関数なので、エラーの場合にはソケットを閉じます。
ライブラリ関数 Misc.tcp_server は Misc.install_tcp_server でソケットを作成した後無限ループに入ります。ループでは accept を使って接続要求を待ち、受け入れた接続は treat_connection 関数を使って処理します。treat_connection はライブラリ関数なことから、accept が途中で終了した場合にはやり直します。また予期しない接続の切断が起こったときにサーバプログラムを終了させるのではなく、EPIPE 例外が treat_connection によって捕捉されるようにsigpipe シグナルを無効化しておきます。接続を閉じるときにディスクリプタ client を閉じるのは例外の有無にかかわらず treat_connection の責任です。
treat_connection 関数はアドレスの他にサーバのディスクリプタも受け取りますが、これは treat_connection 関数が fork や double_fork をした場合でもサーバを閉じられるようにするためです。
以下のアプリケーション特有の service 関数を考えます。この service 関数はクライアントと通信を行ってから接続を閉じます。
この場合サーバは接続を順番に処理することができます。次の Misc モジュールにあるライブラリ関数はこのパターンに対処します:
sequential_treatment 関数を使った場合サーバがあるクライアントを処理している間は他の接続リクエストを処理することができないので、この関数が使えるのは service 関数が決まった短い時間で終わるサービスのときに限られます。
ほとんどのサーバプログラムは accept が返った直後に fork を呼ぶことでサービスの実行を子プロセスに移譲します。子プロセスが接続を処理し、親プロセスはもう一度 accept を行います。Misc モジュールの以下の関数がこの操作を行います。
親プロセスがディスクリプタ client_socket を閉じることが重要であることに注意してください。ここで閉じることを忘れると子プロセスが client_socket を閉じても接続を終了しなくなり、すぐに親プロセスのディスクリプタが枯渇します。このディスクリプタはフォークが失敗したときにも閉じられます。エラーが致命的でなければサーバの実行が続くためです。
同様に、子プロセスは接続リクエストを受け取った server ディスクリプタをすぐに閉じます。一つ目の理由はこのディスクリプタが必要がないことです。二つ目の理由は子プロセスが終了する前にサーバが新しい接続の受け付けを終了する場合があることです。ml+exit 0+ の呼び出しは子プロセスがサービスの実行を終えた後に終了するためおよびサーバループを実行し始めないことを確実にするためにあるので重要です。
今までのライブラリ関数では子プロセスがいずれゾンビプロセスになり回収する必要が生じるというのを無視してきました。この問題の解決方法は二つ考えられます。一つ目のシンプルな方法はダブルフォーク ( ?? ページ参照)を使って孫プロセスに接続を処理させる方法です。この方法では Misc モジュールの以下のライブラリ関数を使います:
しかしこの方法でサーバプロセスが孫プロセスを管理する方法が一切無くなってしまいます。サービスを終了するときにサーバプロセスとサービスを実行している複数のプロセス全てが終了するように、サービスを同じプロセスグループで管理するのが望ましいです。この理由からサーバはフォークを行いながらも子プロセスを回収できるようにしておくことが多いです。例えば sigchld シグナルのハンドラを使うことができます (?? ページの Misc.free_children 関数を参照)。
ソケットには設定できる内部変数がたくさんあります。例えば転送バッファのサイズや転送の最小サイズ、接続を閉じるときの動作などです。
これらの変数は異なった型を持ちます。そのため OCamlには型の数だけgetsockopt 関数と setsockopt 関数があります。getsockopt 関数とその仲間の詳細なリストは OCamlのドキュメントを、getsockopt と setsockopt の厳密な意味は posix のリファレンスをそれぞれ参照してください。
この例で紹介する二つの変数はストリームタイプでインターネットドメインのソケットにしか適用することができません。
tcp プロトコルではソケットの切断にやり取りが必要なために少し時間がかかります。通常は close の呼び出しはすぐに返って切断に必要なやり取りはシステムが行います。次のコードを実行すると sock に対する close がブロックするようになります。この例では全てのデータが送られるか 5 秒が経過するまでブロックします。
SO_REUSEADDR オプションを使うとローカルアドレスに対するソケットを閉じた直後に システムコール bind で再利用することが可能になります (前の接続のデータを受け取ってしまう可能性はあります)。このオプションを使うとサーバを停止してすぐに再起動できるのでテスト用途にとても便利です。
次の server コマンドを作成します:
このコマンドはポート port からの接続リクエストを受け取り、それぞれの接続について cmd を引数 arg1 ... argn として、標準入出力をソケットの接続として実行します。例えば以下のコマンド:
をマシン pomerol で実行し、別のマシンでユニバーサルクライアント (6.6 ページ参照) を以下のように実行します:
クライアントは以下のコマンドを実行したときと同じ出力を表示します:
grep がローカルのマシンではなく pomerol で実行される点が異なります。
server コマンドは多くのサーバが行うコードをまとめていて、特定のサービスやコミニケーションプロトコルの実装は起動されるプログラム cmd に任されています。この意味で service コマンドは ユニバーサルな サーバです。
tcp_server に渡されるアドレスにはプログラムを実行しているマシンのインターネットアドレスが含まれます。このアドレスを取得するには普通 gethostname を使います(11 行目)。しかし一般的には複数のアドレスが一つのマシンを指していることがあります。例えばマシン pauillac のアドレスが 128.93.11.35 だったとしても、ローカルならば (すでに pauillac の中にいるならば)このマシンには 127.0.0.1 を使ってアクセスすることができます。定数インターネットアドレス inet_addr_any を使えば、マシンを指す全てのアドレスにサービスを行うことができます。
サービスは “ダブルフォーク” で処理されます。孫プロセスによって実行される service は標準入力と標準出力、そして標準エラー出力をソケットにリダイレクトしてからコマンドを実行します。サービスの処理をブロックしながら順番に行うことはできないことに注意してください。
クライアントからの接続は server の親プロセスからの介入なしに閉じられます。以下の三つのケースが考えられます。
exit を実行して終了する。これによって標準出力が閉じられ、このディスクリプタはクライアントにつながるソケットの出力を指す最後のディスクリプタであるから、クライアントは次の読み込みで EOF を受け取る。sigpipe シグナルを受け取る場合がある。これによってプロセスが終了するが、誰もコマンドの出力を読んでいないことから、これは問題ない。sigpipe シグナル (あるいは EPIPE 例外) を受け取る。
サーバを書くのはクライアントを書くよりも労力が要ります。クライアントは接続するサーバのことを普通知っているのに対し、サーバはクライアントのことを何も知らないからです。とくにサーバがパブリックな場合、クライアントは “敵” である可能性があります。そのため例外的なケースに対する防御をしなければいけません。
典型的な攻撃は接続を開けた後リクエストを送ることなく開いたままにするというものです。接続を受け入れた後サーバはクライアントが接続している間ずっとブロックします。攻撃者は何もしない接続を大量に開くことでサービスを飽和させることができます。そのためサーバは同時接続数を制限してリソースを枯渇を防ぐと共に、長い間何もしていない接続を終了させる必要があります。
サーバがフォークを行わず、接続を来た順番に処理する場合、このブロッキングの問題が生じることになります。処理している接続は何もしていないにもかかわらず他の接続に応答することができなくなります。順番に処理するサーバに対する解決法として通信の多重化がありますが、これは実装するのが難しくなります。並列サーバはよりエレガントですが、それでもタイムアウトは必要になります。タイムアウトには例えばアラームを使うことができます(4.2 節参照)。
SOCK_STREAM タイプの接続のほとんどで使われる tcp プロトコルではコネクション型通信だけを使うことができます。逆に、SOCK_DGRAM タイプの接続のほとんどで使われる udp プロトコルでは常にコネクションレス型通信が使われ、二つのマシンの間には確立された接続がありません。このタイプのソケットではデータの転送はシステムコール recvfrom と sendto を使って行われます。
転送されたデータのサイズを返すという点で、インタフェースは read と write に似ています。recvfrom は読み込んだバイト数の他にデータを送っているマシンのアドレスも返します。
SOCK_DGRAM タイプのソケットに connect を呼ぶと疑似接続が取得できます。この疑似接続は本当は存在せず、 connect の引数に渡されたアドレスがソケットによって記憶され、データの送受信で使われるようになるというだけです (他のアドレスからのデータは無視されます)。connect を複数回読んでアドレスを変更したり、0 などの無効なアドレスを渡して疑似接続を切断することは可能です。反対にストリームタイプのソケットにこのようなことを行うとエラーが出ます。
システムコール recv と send はそれぞれ read と write に対応しますが、ソケットのディスクリプタ専用です。
recv と send のインタフェースは read と write に似ていますが、msg_flag 型のフラグのリストが引数に追加されています。この型の値と意味を次に示します:
MSG_OOB | アウトオブバンドデータを処理する。 |
MSG_DONTROUTE | デフォルトのルーティングテーブルを使用しない。 |
MSG_PEEK | データを読むことなく確認だけ行う。 |
これらのプリミティブ (原始的な関数) はコネクション型通信通信でも read と write の代わりに利用できるほか、疑似通信モードでも recvfrom と sendto の代わりに利用できます。
ユニバーサルクライアント/サーバの例はよく利用されるので、Unix モジュールにはネットワークサービスを確立したり利用するための高レベルな関数があります。
open_connection は引数のアドレスに対する接続を開き、そのソケットに対する入出力用の Pervasives チャンネルの組を作成します。返り値のチャンネルに対する入出力はサーバとの通信となりますが、チャンネルはバッファされるために、リクエストを本当に送られたことを保証するにはチャンネルをフラッシュする必要があります。クライアントはチャンネルを閉じる (この操作はソケットも閉じます) ことで任意のタイミングで接続を閉じることができるほか、 shutdown_connection を使って “きれいに” 接続を閉じることもできます。サーバが接続を閉じた場合、クライアントは入力チャンネルから EOF を受け取ります。
establish_server 関数でサービスを確立することができます。
establish_server f addr はアドレス addr にサービスを確立し、リクエストを関数 f で処理します。コネクションがあるたびにサーバは新しいソケットを作成してフォークします。子プロセスはクライアントと通信に利用する入出力用の Pervasives チャンネルを作成し fに渡します。f が返ると子プロセスはソケットを閉じて終了します。クライアントが接続をきれいに閉じたならば、子プロセスは入力チャンネルに EOF を受け取ります。そうでなくクライアントが接続を突然閉じた場合には f が書き込みを行おうとしたときに sigpipe を受け取ります。いずれの場合でもこのとき親プロセスは他のリクエストを処理しているはずです。establish_server はエラー (サービスの確立時の OCamlランタイムやシステムのエラーなど) の場合を除いて返りません。
クライアントとサーバの間でやり取りされるデータは単純なプロトコル (rsh, rlogin, …) ではクライアントからサーバへ、およびサーバからクライアントへの二つのバイト列として自然に表現できます。その他のプロトコルではやり取りされるデータはもっと複雑であり、バイト列からデータへ、あるいはデータからバイト列へのデコード/エンコードが必要になります。クライアントとサーバはリクエストの形式と接続で交わされるレスポンスについて取り決めた転送プロトコルについて合意しておく必要があります。Unix コマンドが利用するプロトコルの多くは “rfc” (request for comments) と呼ばれるドキュメントに記載されています。これらのドキュメントは議論のための提案として始まりましたが、時が経ちユーザがこのプロトコルに慣れるにしたがって標準となりました2。
バイナリプロトコルの多くはデータをメモリ内の表現にできるだけ近いコンパクトな形式で転送します。エンコード/デコードに必要な処理を最小化しネットワーク帯域を節約するためです。このタイプのプロトコルの典型的な例は x サーバと x アプリケーションの間の通信で利用される x-window プロトコルと nfs プロトコル (rfc 1094) です。
バイナリプロトコルはデータを次のようにエンコードすることが多いです。整数と浮動小数点数には同じ 1, 2, 4, あるいは 8 バイトのバイナリ表現が使われます。文字列には長さを示す整数とその後に続く内容で表現されます。構造化されたオブジェクト (タプル、レコード) はフィールドを順番通りに並べて表現されます。可変長のオブジェクト (配列、リスト) は長さを表す整数とそれに続く要素で表現されます。転送されるデータの型が正確に分かっているならば、受け取ったプロセスは簡単にメモリ上に復元できます。そうでなく異なるタイプのデータがソケットでやり取りされた場合、データのエンコードはタイプを表すデータ先頭の整数を読み取ってから行われます。
x ライブラリの XFillPolygon 関数は
多角形を塗りつぶす関数であり、以下の形のメッセージを送信します:
FillPoly コマンドの番号)
バイナリプロトコルでは接続するマシンのアーキテクチャに注意する必要があります。例えば複数のバイトからなる整数は ビッグエンディアン のマシンでは最上位バイトを先に (メモリの若いアドレスに) 格納しますが、 リトルエンディアンのマシンでは最下位バイトが先になります。16 ビット整数 12345 = 48 × 256 + 57はビッグエンディアンのマシンではアドレスが n の場所に 48 が、 n+1 の場所に 57 が格納されますが、リトルエンディアンのマシンではアドレスが n の場所に 57 が、 n+1 の場所に 48 が格納されます。このためプロトコルは複数のバイトからなる整数を転送する場合にどちらの方法を使うのかを指定する必要があります。あるいは転送されるメッセージのヘッダにどちらの方法を使うか書くことでどちらも使えるようにすることもできます。
OCamlシステムにはデータ構造をエンコード/デコードする (文献によっては マーシャリング とか シリアライゼーション とか ピックリング などと呼ばれる処理です) ための関数が二つあります。これらの関数を使うと OCamlの値とバイト列の間の変換を行うことができます。
output_values と input_values は値をディスクに保存してあとで読み出せるようにするための関数ですが、任意の値をパイプやソケットへ送ることにも利用できます。関数を除く全ての OCamlの値を処理でき、値の間の共有や循環を保存し、エンディアンの異なるマシン間でも利用できます。これ以上の情報は Marshal モジュールで確認できます。
セマンティクス上は input_value の型が間違っていることを指摘しておきます。全ての型 'a に対して input_value の返り値の型が'a になることはないので、この関数の型は一般的すぎます。input_value の返り値は明確な型であり、全ての可能な型ではありませんが、これをコンパイル時にチェックすることはできません。返り値の型は実行時に入力チャンネルから読み込むデータに依存しているからです。input_value に正しく型検査を行うにはダイナミックオブジェクトと呼ばれる ML 言語の拡張が必要になります。ダイナミックオブジェクトでは値が型と組にされ、実行時の型検査が可能になります。詳細は [15] を参照してください。
x-ウィンドウプロトコルが OCamlで書かれていたならば、サーバへのクエストのためのヴァリアント型 request とサーバからのレスポンスのためのヴァリアント型 reply が定義されていたでしょう。
サーバの主な処理はリクエストをデコードして返事を書くループとなるはずです:
アプリケーションとリンクされる x ライブラリの関数は次のような構造になるでしょう:
バイナリプロトコルのもう一つの使用例は遠隔手続き呼び出しです。遠隔手続き呼び出しとは、マシン A のユーザがマシン B で関数を f を実行するというものです。関数を直接呼び出すことは当然できません。ですが、マシン B に接続して関数を実行し、結果をマシン A に送り返すという作業を呼び出しごとにプログラムすることは可能です。
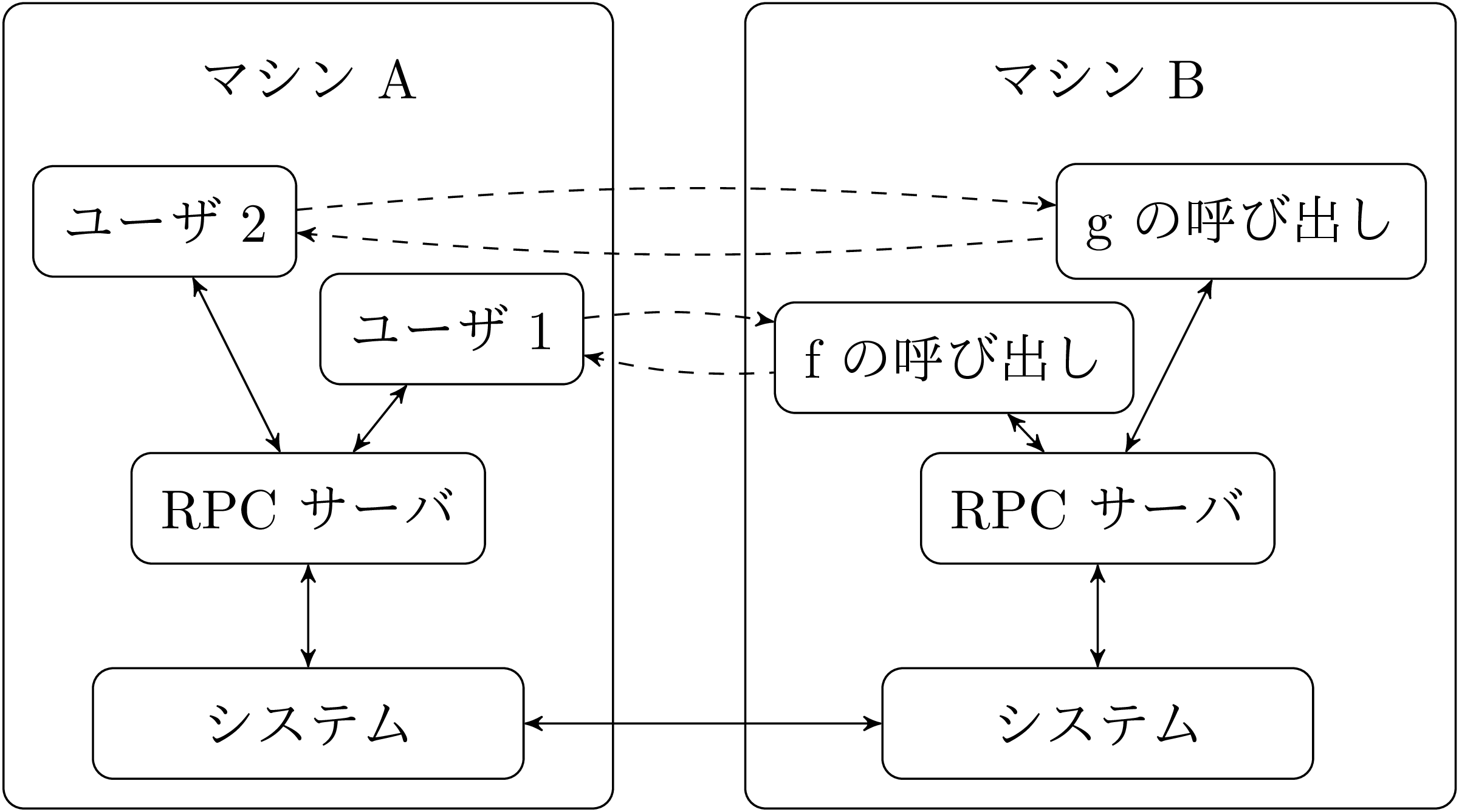
遠隔手続き呼び出しは一般的な状況であるために、これを行う rpc サービスが存在します (図 4)。rpc サーバはマシン A と B の両方で実行され、以下のように動作します。まずマシン A 上のユーザがマシン A 上の rpc サーバに遠隔地のマシン B 上における関数の実行をリクエストします。次にマシン A 上の rpc サーバはリクエストをマシン B 上の rpc サーバにリレーし、マシン B は f を実行して結果をマシン A 上の rpc サーバに送り返します。最後にマシン A 上の rpc サーバが結果をユーザに渡して終わりです。
マシン B 上で実行される他の関数に対する遠隔手続き呼び出しが、マシン A 上の同じ rpc サーバで処理されることになります。マシン A と B にインストールされた rpc サービスの間で接続処理は共有され、ユーザからはこれらの遠隔手続き呼び出しの処理が単純な関数呼び出しに見えます (図の破線)。
プロトコルの効率が重要でないネットワークサービスでは “テキスト” プロトコルがよく利用されます。 “テキスト” プロトコルは実際のところ小さなコマンド言語です。リクエストは複数のコマンドであり、最初の語がリクエストのタイプを、残りの語がコマンドの引数を表します。応答も一つ以上のテキストからなり、大抵は応答の種類を表す数字コードから始まります。“テキスト” プロトコルの例をいくつか示します:
| 名前 | 説明 | 目的 |
| smtp (Simple Mail Transfer Protocol) | rfc 821 | 電子メール |
| ftp (File Transfer Protocol) | rfc 959 | ファイル転送 |
| nntp (Network News Transfer Protocol) | rfc 977 | ニュースの閲覧 |
| http/1.0 (HyperText Transfer Protocol) | rfc 1945 | ウェブの巡回 |
| http/1.1 (HyperText Transfer Protocol) | rfc 2068 | ウェブの巡回 |
これらのプロトコルの大きな利点はクライアントとサーバ間のやり取りが人間にも読めることです。例えば telnet コマンドを使ってサーバと直接対話することができます。host を接続するホストの名前、 service をサーバで実行されたサービスの名前 (http やsmtp、 nntp など) として telnet host service を起動すると、クライアントとしてのリクエストを打ち込ことができ、それに対するサーバからの応答は標準出力に出力されます。これによってプロトコルは理解しやすくなりますが、コーディングとリクエストと応答のデコードはバイナリプロトコルよりも複雑になり、メッセージはより大きく、したがって非効率になる傾向にあります。
シェルから smtp サーバにメールを送ったときの対話ログの例を示します。>> から始まる行はクライアントからサーバへ向かうテキストであり、<< から始まる行はサーバからクライアントへ向かうテキストです。
コマンド HELO、MAIL そして RCPT はそれぞれクライアントのマシン名、送信者のアドレス、受信者のアドレスをサーバに送信します。DATA コマンドは電子メールの本文を送信してよいかをサーバに訪ねます。その後にメールの本文を入力し、 '.' だけからなる行で終了します(この文字だけからなる行をメール本文に含めたい場合には、'.' を二つ書いておけばサーバは一つ目のピリオドを読み飛ばします) 。
サーバからの応答は全てコメントのついた 3 桁の数字コードです。5xx の形をした応答はエラーを表し、 2xx は全てが上手くいっていることを表します。クライアントが実際のプログラムであれば応答コードだけを解釈します。コメントはメールシステムの開発者を助けるために存在します。
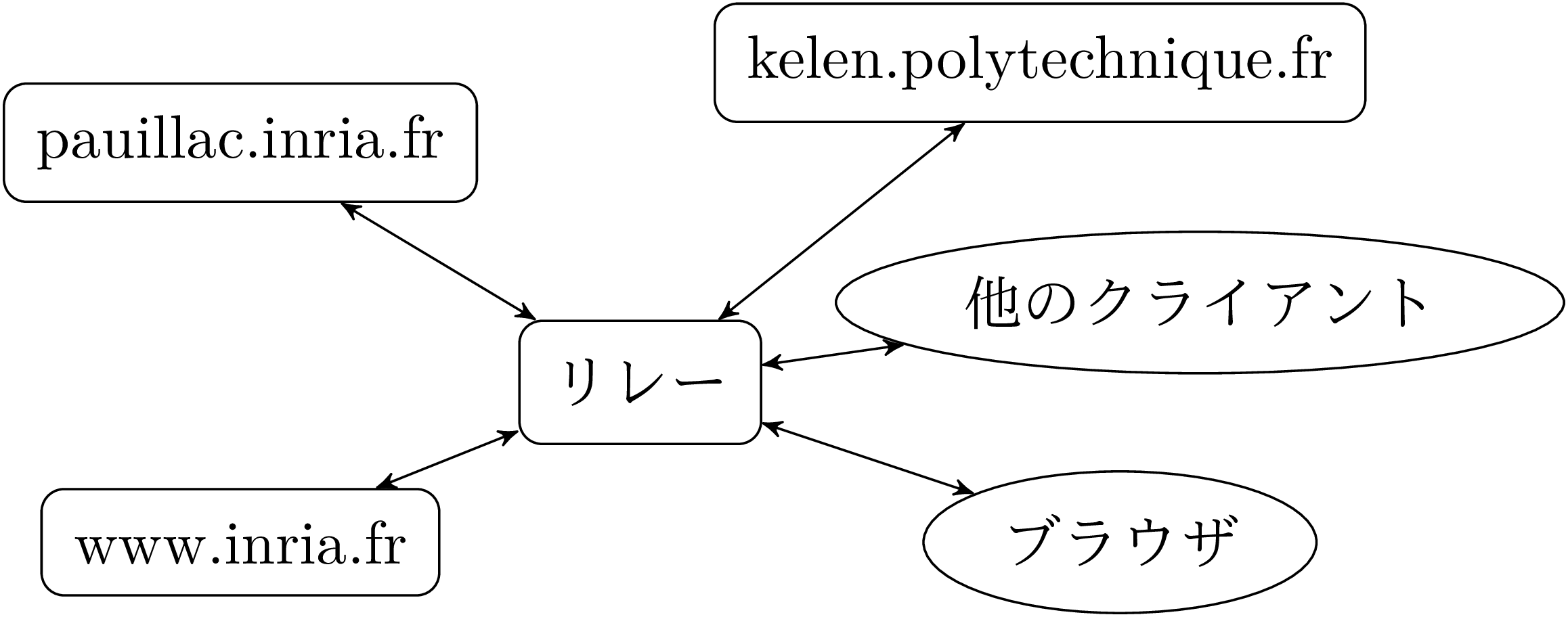
http(HyperText Transfer Protocol) プロトコルは有名な “ワールドワイドウェブ” でドキュメントを読むのに主に使われます。この分野はクライアント-サーバの例のニッチな領域です。ページを読み込むクライアントとページを書き込むサーバの間には無数の中継リレーが存在し、それらは実際のクライアントに対して仮想サーバとして振る舞ったり、物理サーバに対して移譲されたクライアントとして振る舞ったりします。これらのリレーではキャッシングやフィルタリングなどのサービスがよく実行されます。
httpプロトコルにはいくつかのバージョンがあります。本質的な部分、つまりクライアントとリレーのアーキテクチャ、に集中するために、一番最初のバージョンの httpプロトコルを改変したシンプルなプロトコルを使います。このプロトコルはホコリをかぶっていますが、それでもほとんどのサーバによって理解されます。節の最後にはウェブを探索する本物のツールを作るために必要となる、より現代的でより複雑なバージョンのプロトコルを示します。ただし例をこの新しいバージョンに書き直す部分は練習問題として残しておきます。
httpプロトコルのバージョン 1.0 は rfc 1945 で規定され、以下の形のリクエストを定義しています:
ここで sp はスペースを、 crlf は文字列"\r\n" (“リターン” と改行) を表します。この単純なリクエストに対する応答もシンプルであり、応答はヘッダの何もない urlの要素そのものです。
リクエストの終端は EOF によって合図され、そこで接続が閉じられます。バージョン 0.9 のプロトコルから受け継いだこの形のリクエストは一つの接続に対するリクエストを一つだけに制限します。
引数 urlを一つ取り、それが表すウェブ上のリソースを取得して表示するプログラム geturl を作ります。
最初のタスクは urlをパースしてプロトコルの名前 (ここでは "http" でなくてはいけません)、サーバのアドレス、ポート番号 (無くても良い)、そしてサーバ上のドキュメントの絶対パスを取り出すことです。この処理には OCamlの正規表現ライブラリ Str を使います。
次の関数が示すように、シンプルなリクエストの送信は簡単な処理です。
urlはサーバのアドレスとポート番号を含む完全なものであるか、そうでなければアドレスとサーバ上のパスだけが含まれるものであることに注意してください。
応答はドキュメントの内容だけを含み追加の情報を含まないので、応答を読み込むのはより簡単です。リクエストにエラーがあった場合、サーバからはエラーメッセージがhtml ドキュメントとして返ります。このことから、応答がエラーかどうかを確認することなく Misc.retransmit を使って出力すればすむことがわかります。プログラムの残りの部分ではサーバとの接続を確立します。
いつもどおり、コマンドライン引数のパースする処理を追加して完成です。
この節では httpリレー (あるいは プロキシ) プログラムを作成します。このプログラムはクライアントからの httpリクエストを他のサーバにリダイレクト(あるいはリレー) し、応答をクライアントに転送します。
リレーの役割を図 5 に示します。クライアントがリレーを使った場合、そのリクエストは世界中に存在する個々のhttpサーバではなくリレーサーバに送信します。リレーにはいくつもの利点があります。まず、リレーサーバは最後の、あるいは頻繁に送られる応答を記録してリモートサーバに問い合わせることなくリクエストに答えることができます。これによってネットワークの過負荷を避け、サーバがダウンしているときでも応答が得られるようになります。次に、広告や画像の削除といった応答のフィルターを行うことができます。また、ワールドワイドウェブ全体を一つのサーバを通して見るようにすることでプログラムの開発が容易になります。
コマンド proxy port が port 番ポート (省略された場合は httpプロトコルのデフォルトのポート番号) にリレーサーバを作成するようなコマンド proxy を作成します。get_url 関数を作るときに使った関数のコードを Url モジュールに入れて再利用します。書くべきなのはリクエストの解析とサーバの立ち上げの部分だけです。
サービスを確立には establish_server 関数を使うので、定義する必要があるのは接続リクエストを処理する関数だけです:
単純な httpリクエストはリクエストごとに新しい接続を必要としますが、これは非効率です。なぜならリクエストには通常他のリクエストが続くからです(例えばクライアントが画像つきのウェブページを受け取った場合、クライアントは続けて画像をリクエストします)。さらに接続を確立する時間はリクエストを処理する時間を簡単に上回ります(7 章ではプロセスではなくスレッドでリクエストを処理することでこの時間を削減する方法を見ます)。rfc 2068 で規定される httpバージョン 1.1 では一つの接続で複数のリクエストを処理することが可能になる複雑なリクエストが利用されます3。
http/1.1 で使われる複雑なリクエストではサーバは全ての応答の先頭に応答のフォーマットと転送されるドキュメントのサイズを表すヘッダを付けます。これによってサイズが既知となってドキュメントの終端は EOF ではなくなり、更に多くのリクエストを処理できるようになります。複雑なリクエストは以下の形をしています:
header の部分はキーと値からなるフィールドのリストであり、以下の構文を持ちます:
':' の周りに余分なスペースを置くことが許されており、スペースはタブまたは複数のスペースと取り替えることができます。ヘッダフィールドは複数行からなっていても構いません。このとき、およびこのときに限り、行末 crlf の次にスペース sp が続きます。最後に、大文字と小文字はフィールドのキーワードと特定のフィールドの値において無視されます。
フィールドが必須かどうかはリクエストの種類によります。例えば GET リクエストでは目的地となるマシンを示すフィールドが必須です。
この種類のリクエストでは必要に応じて If-Modified フィールドを指定することで、ドキュメントが指定した日時から改変されている場合に限ってドキュメントを返すようにすることができます。
header 内のフィールドの数は前もって定まっていませんが、ヘッダの終わりは crlf だけからなる行で示されます。
以下は完全な例です (各行の最後の \r の次には \n が続きます):
複雑なリクエストに対する応答も複雑になります。応答はステータスを表す行、ヘッダ、そして(もしあれば)応答の本体からなります。
応答のヘッダのフィールドはリクエストのものと似た構文を持ちますが、必須、あるいは必須でないフィールドが異なっています (リクエストの種類と応答のステータスによって異なります — プロトコルのドキュメントを見てください)。
応答の body は空でなければ一つのブロックまたは複数のチャンクで送られます。
body が一つのブロックの場合、ブロックのバイト数を 10 進で表した ascii 文字列を指定する Content-Length フィールドがヘッダに含まれる。body がチャンクで転送される場合、ヘッダは “chunked” という値を持つ Transfer-Encoding フィールドを持つ。データ本体は空のチャンクで終わる複数のチャンクの列であり、各チャンクは以下の形を持つ:
size はチャンクのサイズを 16 進で表し、 chunk はそのサイズのデータ本体である ([ と ] の間の部分は必須ではないので安全に無視できる)。最後の空のチャンクは必ず以下の形式となる:
Content-Length フィールドを持っておらず、チャンクされてもいない場合、データ本体は空である (例えば HEAD リクエストに対する応答はヘッダしか持たない)。
一つのブロックからなる応答の例を示します:
ステータス 200 はリクエストが成功したことを示します。301 は urlが応答の Location フィールドで示される 他の urlにリダイレクトされたことを示します。4XX の形のステータスはクライアントにおけるエラーを、 5XX はサーバにおけるエラーを示します。
リレーにキャッシュを追加してください。ページはハードドライブに保存され、リクエストされたページがキャッシュに存在していてキャッシュが古すぎない場合にはそれを返します。そうでない場合にはサーバは問い合わせを行いキャッシュを更新します。
次の wget コマンドを作ってください。wget u1 u2 ... un は u1, u2, …, un へのリクエストを送り、応答を ./m1/p1, ./m2/p2, …, ./mn/pn に保存します。ここで mi と pi はそれぞれサーバの名前とリクエスト ui の絶対パスを表します。連続するリクエストが同じマシン m に対するものである場合、プロトコルの利点を活かしてコマンドが開く接続はひとつだけにするべきです。パーマネント urlによるリダイレクトは追うようにしてください。以下のオプションを追加することもできるでしょう:
-N | ファイル ./mi/ui が存在しない場合、あるいは urlよりも古い場合にはダウンロードしない |
-r | html フォーマットの応答に含まれる urlを再帰的に全てダウンロードする。 |