


これまでは見てきたのはプロセスを管理する方法とファイルを使って外部環境と通信する方法です。コースの残りの部分では、並列に実行されるプロセス同士がコミュニケーションを取りながら協調する方法を見ていきます。
並列に実行されるプロセス同士がやり取りを行う手段として通常ファイルは十分ではありません。例えば一つのファイルにあるプロセスが書き込み、その内容を別のプロセスが読み込む状況を考えてみてください。やり取りの手段としてファイルを使った場合、読み込み側はファイルが終端に達したことを (read が 0 を返すことで)検出することができますが、その理由が書き込みが終わったためなのかそれとも計算に時間がかかっているためなのかを知ることはできません。さらにファイルはやり取りされるデータを全て保持する必要があるので、ディスクを不必要に圧迫します。
パイプはこのようなやり取りに向いた仕組みです。パイプは二つのファイルディスクリプタからなります。一つがパイプの出力を表し、もう一方がパイプの入力を表します。パイプはシステムコール pipe で作成できます。
pipe を呼ぶと (fd_in, fd_out) が返ります。fd_in は 読み込み専用 で開かれたパイプの出力を表すファイルディスクリプタで、fd_out は 書き込み専用 で開かれたパイプの入力を表すファイルディスクリプタです。パイプ自身はこれら 2 つのディスクリプタからのみアクセス可能なカーネルの内部オブジェクトです。またパイプはファイルシステムにおいて名前を持ちません。

パイプは先入れ先出しのキューのように振る舞います。最初にパイプに書き込んだものが最初にパイプから読み込まれます。書き込み (パイプの入力ディスクリプタへの write) はパイプを満たし、パイプが満杯の場合はブロックします。ブロックは他のプロセスがパイプの他方の端から十分な量のデータを読み込むまで続き、write に渡された全てのデータが書き込まれるまで続きます。読み込み (パイプの出力ディスクリプタへの read) はパイプの中身を消費します。パイプが空のとき read はパイプの他方の端に少なくとも 1 バイトが書き込まれるまでブロックします。read は要求されたバイト数だけ読み込むまで待つこと無く返ります。
入出力が同じプロセスから起きるのならばパイプは役に立ちません。そのようなプロセスは大量の書き込みや空のパイプへの読み込みによって永遠にブロックしてしまうからです。そのため普通パイプへの入出力は別々のプロセスが行います。パイプは名前を持たないことから、パイプを利用するプロセスの片方はパイプを作成したプロセスからのフォークによって作られる必要があります。
次の短いコードは典型的なパイプの使用例です。
fork のあとパイプの入力を指すディスクリプタは二つあり、親プロセスと子プロセスが一つづつ持っています。出力用ディスクリプタについても同様です。
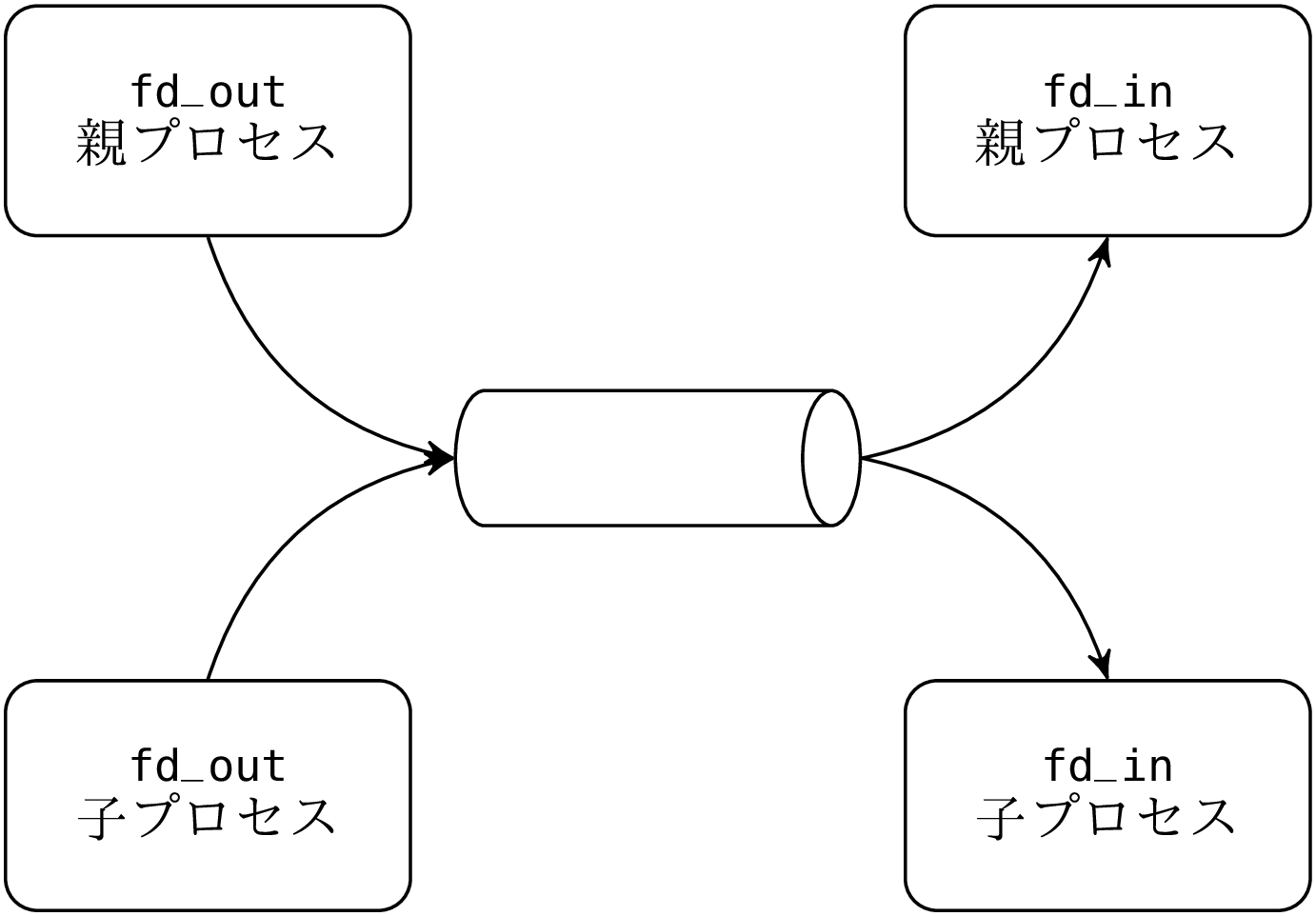
この例では子が書き込みを、親が読み取りを行います。子はパイプの出力 fd_in をクローズしますが、これはディスクリプタを節約しプログラミング上のミスを防ぐためです。ディスクリプタはプロセスのメモリに確保され、フォークすると親子でメモリが別々になるので、子プロセスでディスクリプタをクローズしたとしても親プロセス fd_in はその影響を受けません。パイプはシステムメモリに確保され、親プロセスの fd_in がパイプの出力に読み込みモードで開いている限り生き続けます。同じ理由で親プロセスはパイプの入力へのディスクリプタをクローズします。結果的に以下のような状態となります:
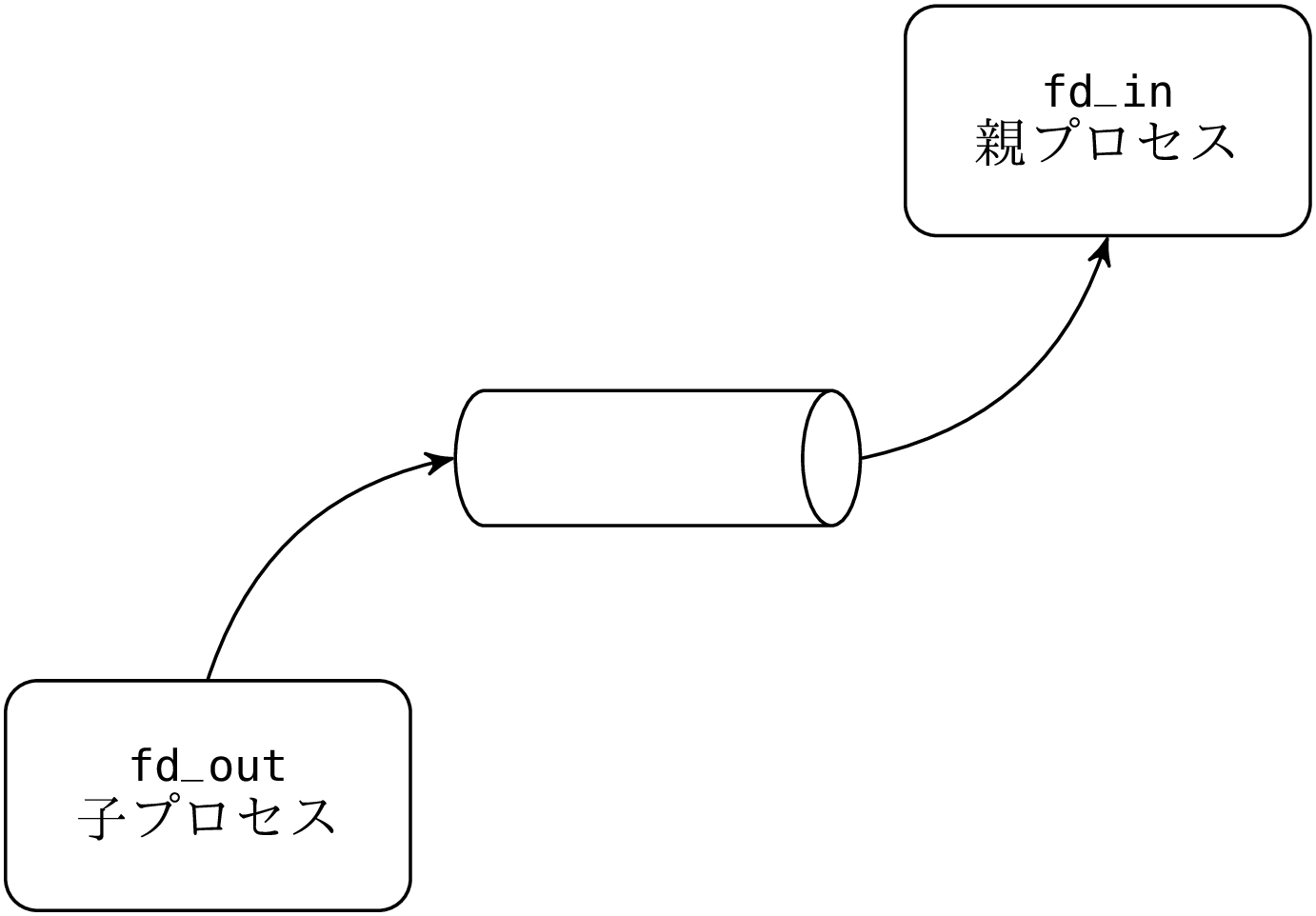
子プロセスが fd_out に書き込んだデータは親の fd_in に書き込まれます。
パイプの入力へのディスクリプタが全てクローズされかつパイプが空のとき、パイプの出力への read は 0 (ファイルの終端) を返します。パイプの出力へのディスクリプタが全てクローズされているとき、パイプの入力への write は書き込みプロセスを終了させます。より正確に言うと、カーネルが write を呼んだプロセスに sigpipe シグナルを送り、このシグナルのデフォルトの動作がプロセスの終了です。sigpipe シグナルのハンドラが変更していた場合は、 write は EPIPE エラーを出して失敗します。
これは並列プログラミングの古典的な例です。ここで扱うのは素数を順に列挙しながら見つかった順にインタラクティブに表示するという問題です。アルゴリズムのアイデアは次のようなものです。あるプロセスが 2 から順に整数を出力します。このプロセスに整数 p を一つ受け取って表示する別の フィルター プロセスをつなげます。
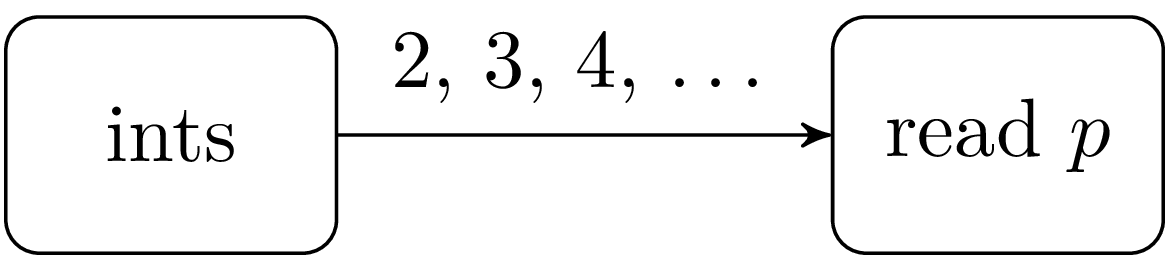
最初のフィルタープロセスは 2 を最初に受け取ることから p=2 となります。このプロセスは自分の出力と接続した新しいフィルタープロセスを作成します。そして新しいプロセスに p の倍数でない整数を入力します。

新しいフィルタープロセスは 3 を最初に受け取るので p=3 となります。このプロセスは 3 の倍数をフィルターし、同じことが次のプロセスへと続きます。
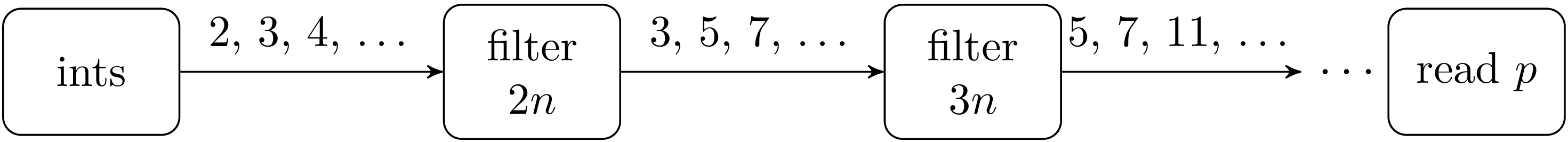
このアルゴリズムは見つける素数の数よりひとつ多い数のプロセスが必要になりますが、これだとプロセスを多く作りすぎるのでUnix で直接実装できません。多くの Unix システムではプロセス数を数十程度に制限しています。同時に実行されるプロセスが多すぎる場合、プロセスが一つしか無い機械ではコンテキストスイッチによるコストによって性能が大幅に減少します。そのためこれからの実装ではプロセスは最初の n 個の素数 p1, …, pn を出力し、p1, …, pn の倍数でない整数を次のプロセスへと渡します。n=1000 程度にすればプロセス生成のコストが見えなくなります。
まず 2 から k までの整数を生成するプロセスを作ります。
整数の入出力には次の関数が使われます:
標準ライブラリの output_binary_int 関数は整数を表す 4 バイトのバイナリをout_channel に書き込みます。この整数は in_channel に対する input_binary_int で読み込むことができます。これらの関数を使うことには二つのメリットがあります。まず、整数をバイト表現に変換する関数を作る必要がありません1。さらに、これらの関数はバッファされた i/oを使うのでシステムコールの回数が減り、パフォーマンスが上昇します。次の関数は i/oをバッファするための in_channel または out_channel を作成します。
これらの関数を使うと間接的に手に入れたディスクリプタ、あるいはファイルを開いていないディスクリプタに対してバッファされた i/oを行うことができます。バッファされた i/oをバッファされていない i/oと混ぜることはしてはいけません。混ぜることは不可能ではありませんが、とてもエラーを含みやすい — 特に入力に対しては — ので決して行うべきではありません。また一つのディスクリプタに対して二つ以上の in_channel あるいは out_channel を開くことも可能ですが、これも危険なので行うべきではありません。
フィルタープロセスの話を進めます。このプロセスは補助関数 read_first_primes を使用します。read_first_primes input count は count 個の素数を input (in_channel 型の値) から読み、すでに計算された素数は読み飛ばします。count 個の素数は読み込まれた時点で出力され、計算された素数を保存するリストに入ります。
フィルター関数は以下のようになります:
フィルタは read_first_primes を呼んで最初の 1000 個の素数を出力するところから始まります(引数 input は in_channel 型です)。そのあとパイプを作ってから子プロセスをフォークします、親プロセスは整数を入力 input から読み、それが最初に計算した 1000 個の素数の倍数でない場合はそれをパイプに入力します。
最後に整数を出力するプロセスと最初のフィルタープロセスをつなぐ処理を書けばメインプログラムの完成です。プログラムを sieve k で起動すると k より小さい素数が列挙されます。k が省略された場合には k は max_int となります。
この例では親プロセスが終了するときに子プロセスの終了を待つことはしません。この理由は親プロセスが子プロセスの ジェネレータ であるためです。
k が与えられたとき最初に実行を終えるのは親プロセスであり、終了するとき子プロセスに繋がったパイプの入力へのディスクリプタをクローズします。OCamlはプロセスが終了するときに書き込みモードで開かれたディスクリプタのバッファを空にすることから、子プロセスは親プロセスが書き込んだ最後の整数まで読みきることができます。その子プロセスが終了するときについても同様です。そのためこのプログラムでは子プロセスは一時的に親を失って init の子となります
k が与えられていない場合はいずれかのプロセスが終了するまで全てのプロセスがずっと動き続けます。プロセスの終了すると上記のように子プロセスも終了します。またプロセスが終了すると親プロセスにつながっているパイプの出力をクローズするので、親プロセスは次の書き込みをしたときに終了します (正確には書き込みのときに sigpipe を受け取り、そのデフォルトの動作によって終了します)。
素数が見つかったとき、print_prime 関数は print_newline () を実行します。この実行によって出力のバッファを空にするシステムコールが呼ばれるので、プログラムの実行速度が制限されます。print_newline () は print_char '\n' と flush Pervasives.stdout を実行しますが、フラッシュを省略して print_newline () を print_char '\n' と置き換えた場合何が起こるでしょうか? この問題を解決するにはどうすればよいでしょうか?
解答
いくつかの Unix システム (System V, SunOS, Ultrix, Linux など) ではファイルシステム内で名前を持つパイプを作成できます。この 名前付きパイプ (あるいは fifo) を使うと親子関係にないプロセス同士がやり取りを行うことができます。パイプを作ったプロセスとその子でしかやり取りのできない通常のパイプとは対称的です。
システムコール mkfifo は名前付きパイプを作成します:
第一引数がパイプの名前を、第二引数がアクセス権限を表します。
名前付きパイプは openfile を使って通常ファイルと同じように開くことができます。名前付きパイプの入出力も通常ファイルと同じです。名前付きパイプを読み込み専用 (あるいは書き込み専用) モードで開くとそのパイプが別のプロセスによって書き込みモード (あるいは読み込みモード) で開かれるまでブロックします。すでに開かれていた場合にはブロックはありません。O_NONBLOCK フラグでパイプを開くことでブロックを避けることができますが、この場合パイプへの入出力もブロックしなくなります。clear_nonblock を使うとパイプを開いた後で入出力をブロックするように変更でき、set_nonblock を使うとブロックしないようにすることができます。
ここまでの説明では、シェルが cmd1 | cmd2 のようなコマンドを実行するときのように標準入出力をパイプに接続する方法はわかりません。pipe で作ったパイプの両端を指すのは 新しい ディスクリプタであり、stdin や stdout、 stderr ではないからです。
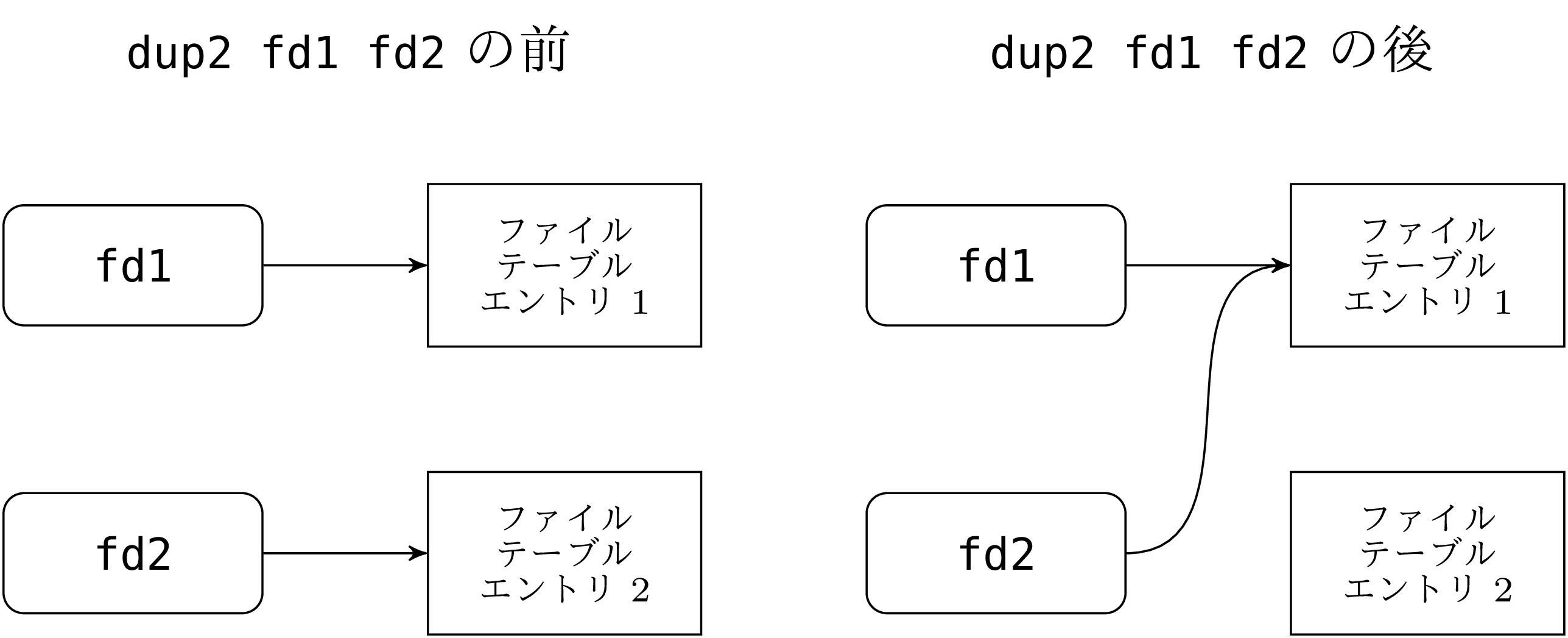
この問題に対処するために、Unix には dup2 というシステムコールがあります (dup2 は「あるディスクリプタを別のディスクリプタに複製する (duplicate to)」 と読めます) 。dup2 はあるディスクリプタを別のディスクリプタとして振る舞うようにします。これが可能なのはファイルディスクリプタ (file_descr 型のオブジェクト)と ファイルテーブルエントリ と呼ばれるカーネル内部のオブジェクトとの間に間接参照の仕組みが存在するからです。 ファイルテーブルエントリ が開かれているファイルやパイプ、現在の入出力位置などの情報を保持します。
dup2 fd1 fd2 を呼ぶとディスクリプタ fd2 が fd1 の指すファイルテーブルエントリを指すようになります。この呼び出しの後には同じファイルまたはパイプを指し、同じ入出力位置を持つファイルディスクリプタが二つあることになります。
標準入力のリダイレクト
dup2 を呼ぶとディスクリプタ stdin はファイル foo を指すようになります。つまり stdin を読み込むとファイル foo から読むことになります (fd への読み込みも同様ですが、これは使用しないのですぐに閉じます) 。stdin の設定は execvp で保存されるので、プログラム bar は標準入力がファイル foo に繋がった状態で実行されます。これはシェルで bar < foo としたときと同じ動作です。
標準出力のリダイレクト
dup2 を呼ぶとディスクリプタ stdout はファイル foo を指すようになります。つまstdout への書き込みはファイル foo への書き込みとなります (fd への書き込みも同様ですが、これは使用しないのですぐに閉じます) 。stdout の設定は execvp で保存されるので、プログラム bar は標準出力がファイル foo に繋がった状態で実行されます。これはシェルで bar > foo としたときと同じ動作です。
あるプログラムの出力を他のプログラムの入力にする
プログラム cmd2 は標準入力がパイプの出力となった状態で実行されます。それと並行してプログラム cmd1 は標準出力がパイプの入力となった状態で実行されます。結果として cmd1 が標準出力に書いたものはすべて cmd2 が標準入力から読みます。
cmd1 が cmd2 よりも前に終了すると何が起こるでしょうか? cmd1 が終了すると全ての開かれているディスクリプタが閉じられるので、パイプの入力を指すディスクリプタがなくなります。結果として cmd2 がパイプにあるデータを全て読んだ次の読み込みで EOF を読み込みます。cmd2 は標準入力が末尾に達したときの動作を行います — 例えば終了するなどです。
反対に cmd2 が cmd1 よりも前に終了した場合、パイプの出力を指す最後のディスクリプタが閉じられるので cmd1 は次に標準出力に書き込んだときに sigpipe シグナルを受け取ります (このシグナルのデフォルトの動作はプロセスの終了です)。
二つのディスクリプタを交換する場合には注意が必要です。dup2 fd1 fd2; dup2 fd2 fd1 では上手く行きません。一つ目の dup2 によって fd1 と fd2 の両方のディスクリプタがファイルテーブルエントリ内の同じファイルを指すようになるので、最初に fd2 に指されていた値は失われ、二つ目の dup2 は意味を持ちません。ここで行いたいのは 2 つの参照セルの交換なので、片方の値を保存しておく一時的な変数が必要になります。システムコール dup によってディスクリプタをコピーして保存することができます。
dup fd は fd が指すファイルテーブルエントリと同じファイルを指す新しいディスクリプタを返します。これを使うことで、例えば stdout と stderr の交換は次のように行なえます:
ディスクリプタのリークを防ぐために交換の後で tmp をクローズします。
以下のようなコマンドを作成します:
このコマンドは次のシェルコマンドのように動作します:
処理の大部分は 6 行目から始まる for ループが行います。最後のコマンドを除いた各コマンドについて、新しいパイプと子プロセスを作成します。子プロセスはパイプの入力を標準出力に接続してからコマンドを実行します。fork のあと子プロセスは親プロセスの標準入力を引き継ぎます。メインプロセス (親プロセス) はパイプの出力を標準入力としてループを続けます。i 番目の反復において以下のような状況になると (帰納法の仮定として) 仮定します:
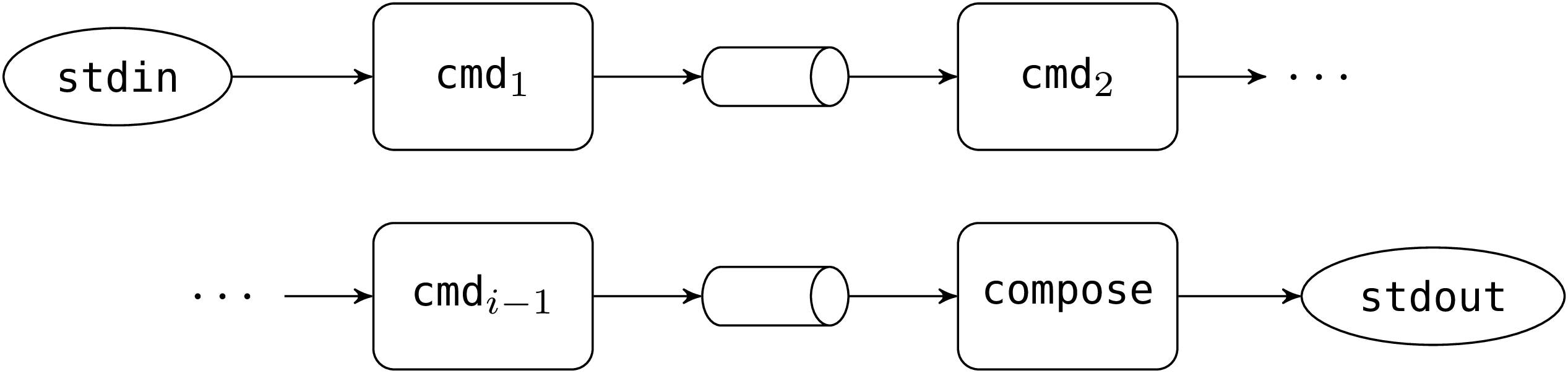
丸角の四角形がプロセスを表します。プロセスの標準入力を左に、標準出力を右に示しています。楕円は compose プロセスの最初の標準入出力を表します。この状態から pipe と fork を実行すると以下のような状況となります:

親プロセスが dup2 を実行すると、こうなります:

子プロセスが dup2 と execv を実行すると、こうなります:

これで次の反復への準備が整います。
最後のコマンドではパイプを作る必要がないのでループの外でフォークが実行されます。compose プロセスの標準入力 (最後から二番目のコマンドの出力) と標準出力(最初 compose コマンドに与えられたもの) が最初から正しいので、ただ fork と exec 呼ぶだけで十分です。親プロセスはそれから子プロセスの終了を待つためにwait を ECHILD エラー (終了待ちの子がいない) が出るまで繰り返し呼びます。子プロセスのリターンコードはビットごとの “or” (lor 演算子) によってまとめられ、compose の返り値となります。これによって全ての子プロセスが 0 を返した場合には 0 が、そうでない場合には 0 以外が compose コマンドから返ります。
/bin/sh を使ってコマンドを実行していることに注意してください。次のようなコマンドを単語に分割する処理を /bin/sh に任せています:
ミニシェルの例のようにこの処理を自分で書くこともできますが、コードを不必要に複雑にしてしまうだけでしょう。
これまでの全ての例において、プロセス間の通信は 線形 でした。つまりそれぞれのプロセスが読み込むのは多くとも一つのプロセスからのデータでした。この節では 複数の プロセスからのデータを読み込む問題の解決方法を見ていきます。
複数のウィンドウを持つ端末エミュレータを例として考えます。あるコンピュータ (クライアントと呼びます) がシリアルポートで Unix マシンに接続しており、Unix マシン上の異なるプロセスに接続するためにクライアント上で複数のウィンドウをエミュレートする必要があるとします。例えばウィンドウの一つはシェルに、他のウィンドウはテキストエディタに使いたいという状況です。シェルからの出力は最初のウィンドウに、テキストエディタからの出力は二番目のウィンドウに表示します。最初のウィンドウがアクティブならばクライアントのキーボードからの入力はシェルに送られ、二番目のウィンドウがアクティブな場合はエディタに送られます。
Unix マシンとクライアントの間には物理的な接続が一つしか無いことから、データの送受信を分割してウィンドウとプロセスの間に仮想的な接続を多重化する必要があります。シリアルポートには次のプロトコルを使用してメッセージを送ります:
Unix マシンではユーザプロセス (シェルやエディタなど) はパイプによって一つ以上の補助プロセスに接続され、補助プロセスはデータの多重化 (あるいは逆多重化) やシリアルポートへの入出力を行います。シリアルポート (例えば /dev/ttya) はスペシャルファイルであり、補助プロセスがクライアントとやり取りを行うために使われます。
逆多重化 (クライアントからユーザプロセスへのデータ転送) は難しくありません。シリアルポートからデータを読み、抽出したデータを目的のユーザプロセスの標準入力に接続されたパイプに書き込めばよいです。
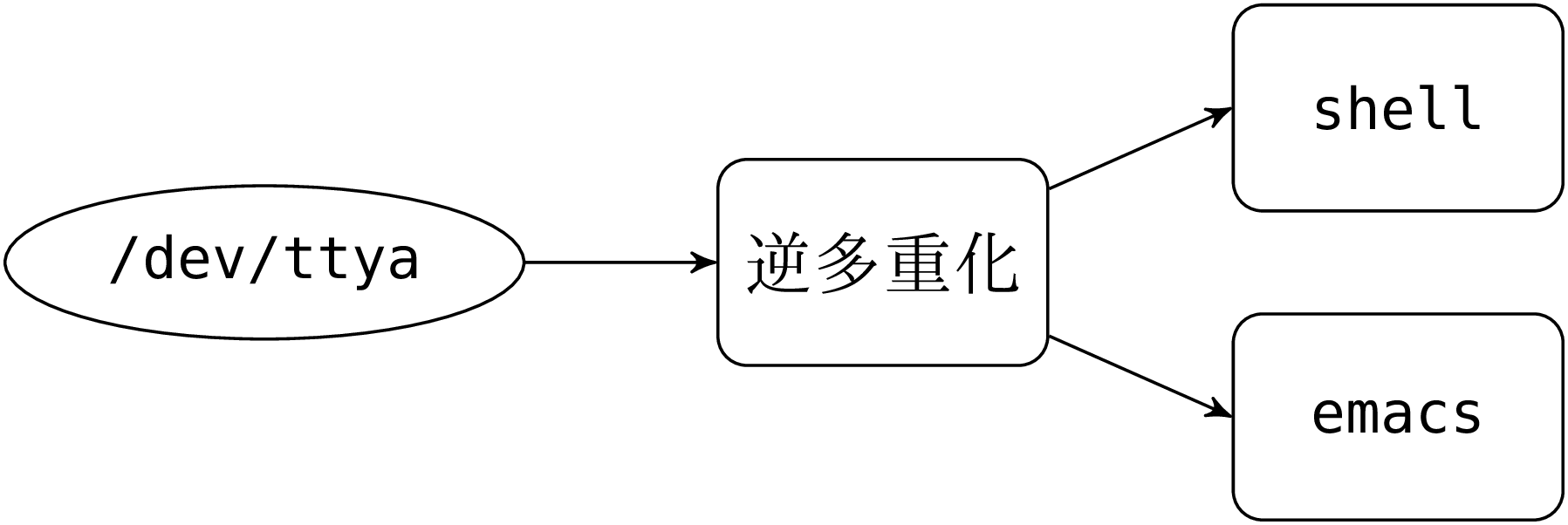
多重化 (ユーザプロセスからクライアントへのデータ転送) はもっと複雑になります。まず逆多重化と同じようなことを試してみましょう。ユーザプロセスの標準出力に接続されたパイプからの出力を読み込み、受信者のウィンドウ番号とデータの長さをつけてシリアルポートに送るプロセスです。

パイプからの読み込みがブロックする可能性があるので、これは上手く行きません。例えばシェルからの出力を読み込みを行ない、その時点では表示するものがなかった場合、多重化プロセスはブロックし、エディターからの文字列は無視されます。表示されるべきデータがあるのはどちらのプロセスのパイプなのかを事前に知る方法はありません(並列アルゴリズムにおいては、あるプロセスが共有リソースへのアクセスをずっと拒否される状況を 飢餓 と言います)。
次に別のアプローチを示します。各ユーザプロセスに リピータ プロセスを結びつけます。このリピータはユーザプロセスの標準出力に接続したパイプの出力を読み、データをメッセージに変換し、メッセージをシリアルポートに直接書き込みます。各リピータプロセスは /dev/ttya を書き込みモードで開きます。

各ユーザプロセスの出力は独立して転送されることから、ブロッキングの問題は解決されます。しかしこの方法を使うとプロトコルが破られる場合があります。二つのリピータが同時にメッセージを書き込んだ場合、 Unix カーネルはそれらの書き込みの原始性、すなわち書き込みが割り込まれることなく行われなければいけないことを考慮することができません。そのため書き込みは最初にメッセージの一部を送り、その次に別のメッセージを送ってから、最初のメッセージの残りの部分を送るかもしれません。クライアントの多重化プロセスはこれに対処できず、二番目のメッセージを最初のメッセージの後半部分と解釈し、それ以降のデータを次のデータのヘッダと解釈するでしょう。
これを避けるためには、シリアルポートに書き込むプロセスがどんなときでも多くとも一つになるようにリピータプロセス同士が同期する必要があります (並列アルゴリズムではこのことを「リピータのシリアル接続へのアクセスは排他制御される必要がある」と言います)。技術的には、これまでに見た概念でこれを行うことができます。リピータはメッセージを送る前に特定のファイル (“ロック”) を O_EXCL フラグで作成し、シリアルポートへの書き込みが終わった後にそのファイルを削除するようにすればよいです。しかしロックの作成と削除にコストが掛かり過ぎるので、あまり効率的とは言えません。
より良い解決法は最初のアプローチ (一つの多重化プロセス) をとり、ユーザプロセスの標準出力に接続されたパイプからの出力を set_nonblock によってノンブロッキングに設定することです。空のパイプからの読み込みはブロックせずすぐに EAGAIN または EWOULDBLOCK エラーを出して返るので、このエラーは無視して次のプロセスの出力を読みにいくことができます。こうすることで飢餓と排他制御の問題を回避できます。しかしこれはとても非効率的な方法でもあります。多重化プロセスがデータを送っているプロセスがなくても実行を止めず、“ビジーウェイト” と呼ばれることを行うためです。この非効率性は読み込みループに sleep を入れることで緩和できますが、残念ながら sleep する正しい時間を見つけるのはとても難しいです。sleep が短いとデータが少ないときにプロセッサに無駄な負荷がかかり、sleep が短いとデータが多いときに知覚可能なレベルの遅延を引き起こすためです。
これは深刻な問題であり、bsd の設計者たちはこの問題を解決するために select という新しいシステムコールを Unix に追加しました。このシステムコールはほとんどの Unix で利用可能です。select を呼ぶと一つ以上の入出力のイベントを (受動的に) 待つことができます。ここでイベントとは以下のことです:
システムコール select は次のシグネチャを持ちます:
最初の三つの引数がディスクリプタの集合をリストで表します。最初の引数が読み込みイベントを監視するディスクリプタの集合で、二つ目が書き込みイベントを監視するディスクリプタの集合、三つ目が例外的なイベントを監視するディスクリプタの集合です。第四引数はタイムアウトまでの秒数です。第四引数が 0 以上のとき、select はイベントが何も起こらなかったとしてもその時間が経てば返ります。この値が負のとき、select は監視を要求されたイベントの一つが起こるまでブロックします。
select はディスクリプタのリストの三つ組を返します。最初の要素が読み込みの準備ができたディスクリプタを、二つ目の要素が書き込みの準備ができたディスクリプタを、三つ目の要素が例外的な条件が真となったディスクリプタをそれぞれ表します。イベントが起こる前にタイムアウトした場合、これら三つのリストは全て空です。
以下のコードはディスクリプタ fd1 と fd2 の読み込みイベントを監視し、 0.5 秒後に返ります。
以下の multiplex 関数は説の最初で説明したマルチウィンドウに対応したターミナルエミュレータの多重化/逆多重化の中心となります。
単純のために、多重化関数はメッセージの受信者番号を送信者番号と同じようにラベル付けし、逆多重化関数は受け取ったデータを受信者番号に直接リダイレクトすることにします。つまり、ユーザプロセスとクライアントのどちらについても、送信者は必ず同じ番号の受信者とやり取りをすると仮定します。あるいは同じことですが、送信者と受信者の対応付けはシリアル接続の内部で受信者番号を書き換えることで行われると仮定します。
multiplex 関数はシリアルポートへ開いたディスクリプタと同じサイズのディスクリプタの配列二つを受け取ります。配列の一つにはユーザプロセスの標準入力につながったパイプが、もう一方にはユーザプロセスの標準出力に繋がったパイプが含まれています。
multiplex 関数は読み込みに使うディスクリプタの集合 input_fds を作るところから始まります。この集合にはユーザプロセスの標準出力につながっているディスクリプタとシリアルポートのディスクリプタが含まれます。一番外側の while の反復では select を呼んで input_fds 内に書き込み待ちがないか確認します。ここでは例外的なイベントを待つことはせず、待ち時間に制限を設けることもありません。select が返ったならば、ユーザプロセスからの入力ディスクリプタまたはシリアルポートのディスクリプタが入力を待っているかを調べます。
ユーザプロセスからの入力ディスクリプタの準備ができているならば read でデータをバッファに読み、メッセージのヘッダをつけてシリアルポートに書き込みます。read が 0 を返した場合対応するユーザプロセスのパイプが閉じられたことを意味します。クライアントのターミナルエミュレータは 0 バイトのメッセージによってウィンドウに対応する番号のユーザプロセスが終了したことを通知されるので、そのウィンドウを閉じることができます。
シリアルポートにデータがある場合、まず 2 バイトのヘッダから受信者番号 i と読み込むデータのバイト数 n を読み込みます。その後シリアルポートのチャンネルから n バイトを読み、読み込んだデータをi 番目のユーザプロセスの標準入力に書き込みます。このとき n が 0 ならば、 i 番目の出力ディスクリプタを閉じます。接続先のターミナルエミュレータが発する n = 0 というメッセージはそのエミュレータのプロセスの標準入力が終端に達したことを意味するからです。
really_read が End_of_file 例外を出したら一番外側のループを抜けます。この例外はシリアルポートが EOF に達したことを意味します。
Unix モジュールの write 関数は要求されたデータがバイト数まで全て書き込まれ終わるまでシステムコール write を呼び続けます。
ディスクリプタがパイプ (あるいはソケット、 6 参照) だった場合、書き込みはブロックしシステムコール write はシグナルによって中断する可能性があります。このような場合には OCamlの Unix.write は中断され EINTR エラーが出ます。ここで問題となるのはシステムコール write によってデータの一部が書き込まれたにも関わらずそのサイズがわからないまま失われてしまうということです。このためシグナルがある状況では Unix モジュールの write は役に立たなくなってしまいます。
この問題を解決するために、 Unix モジュールには single_write という名前の “生の” システムコールがあります。
single_write を使えば、エラーが起こったときにデータが書き込まれていないことを保証できます。
この説の残りではこの関数をどうやって実装するかを示します。基本的にこれは OCamlと C の間のインターフェースの問題です (OCamlのマニュアルにはこの話題に関する情報が載っています) 。次のコードは single_write.c に保存されます:
最初の二行は標準の C ヘッダをインクルードします。その次の四行はディストリビューションと共にインストールされる OCaml特有の C ヘッダをインクルードします。unixsupport.h ヘッダは OCamlの Unix ライブラリが持つ再利用可能な C の関数を定義しています。
一番重要な行は write を呼ぶ行です。この関数は (ディスクリプタがパイプかソケットの場合に) ブロックすることがあるので、呼び出す前に OCamlランタイムのグローバルのロックを開放し (20 行目) 、呼び出した後にロックを取得します (22 行目)。これによってこの関数は Thread モジュール (7 章参照) と同時に利用できます。ブロックしている間に他のスレッドが実行できるからです。
システムコールの間に OCamlはガベージコレクションが実行され、OCamlの文字列 buf がメモリ内を移動する可能性があります。この問題を解決するために buf を C の文字列 iobuf にコピーします。これには追加のコストがかかりますが、10% 前後のオーダーです (50% 程度と考えるかもしれませんが、そうではありません)。関数全体のコストはシステムコールがほとんどを占めるためです。バッファに使う C の文字列の大きさは unix_support.h に定義されています。システムコール中にエラーが起こった場合 (負の返り値で示されます) そのエラーは uerror 関数によって OCamlに運ばれます。 uerror 関数は OCamlの Unix ライブラリで定義されています。
この関数を OCamlから利用するには、 unix.mli を作って以下の宣言を書きます:
実際に使うときには関数を呼ぶ前に引数を確認します:
single_write 関数はバージョン 3.08 から Unix モジュールで利用可能ですが、上記のように自分で書いた場合には以下のようにしてコンパイルする必要があります(OCamlのコードは write.mli と write.ml にあると仮定します)。
通常は以下のようにして C と OCamlのコードを両方含むライブラリ write.cma を使ったほうが実用的です。
ライブラリ write.cma は unix.cma のように使えます。
single_write の動作はシステムコール write によく似ていますが、書き込む文字列がとても長い場合の動作だけ異なります。文字列が UNIX_BUFFER_SIZE よりも長い場合一度のシステムコールで全てのデータを書き込むことができないので、システムコールは繰り返されます。そのためシステムコール write が持つ通常ファイルに対する書き込みの原子性は single_write では長い文字列に対しては成り立ちません。この違いは通常重要ではありませんが意識しておくべきでしょう。
この関数を元にして更に高レベルの関数 really_write を実装することができます。要求されたデータを (アトミックでなく) 全て書き込むので、multiplexer 関数で使った readlly_read 関数に似ています。