


Unix において “ファイル” という言葉はいくつかのものを表します:
ファイルという表現にはファイルが保持するデータだけではなく、その種類やアクセス権限、最終更新日時といったファイルそのものに関するデータ (メタ属性と呼ばれます) も含まれます。
大ざっぱにいって、ファイルシステムは木と考えることができます。根 (ルート)は / で表され、枝は '\000' と / を除く文字列からなるファイルの名前でラベル付けされます (ただし空白文字と印字できない文字は避けたほうが良いとされます) 。終端でないノードは ディレクトリ です: これらのノードは必ず二つの枝 . と .. を含み、それぞれこのディレクトリそのものと親のディレクトリを表します。ディレクトリでないノードのことを ファイル と呼ぶことがありますが、木のどのノードもファイルであることを考えると、これは曖昧です。曖昧さを避けるために、このノートではこれらのことを 非ディレクトリファイル と呼ぶことにします。
木のノードはパスを使って表すことができます。パスの始点がファイル階層の頂上である場合、そのパスは 絶対 です。一方始点がディレクトリである場合にはパスは 相対 です。より正確に言うと、 相対パス とはファイルの名前を / で区切った文字列であり、絶対パス とは先頭に / のついた相対パスです。ここでは同じ文字 / が区切り文字と根ノードという二つの意味で使われています。
Filename モジュールを使うとパスをポータブルに扱うことができます。例えば concat は / という文字を与えることなく二つのパスを結合するので、他のオペレーティングシステム (windows では区切り文字は \ です) でも同じような動作をさせることができます。Filename モジュールには current_dir_name とparent_dir_name があり、それぞれ . と .. という枝を表します。basename 関数と dirname 関数はパス p を受け取ってそれぞれディレクトリ名 d と非ディレクトリファイル名 bを返します。このとき p と d/p が表すファイルは同じになります。Filename モジュールの関数はパスの操作だけを行うので、実際にそのパスが存在するかどうかは考慮しません。
ファイル階層は厳密には木ではありません。. と .. というディレクトリが自分自身や上の階層のディレクトリを指しているからです。さらに、非ディレクトリファイルは複数の親を持つことができます (ハードリンク と言います)。また他のファイルへのパスを保持する非ディレクトリファイルとみなすことができる シンボリックリンク もあります。概念上は、シンボリックリンクの保持するパスは通常ファイルと同じようにその内容を読むことで取得できます。パスの途中でシンボリックリンクに当たった場合、そのたびにパスをたどります。s が l へのシンボリックリンクならば、 p/s/q というパスは l が絶対パスのときは l/q を、相対パスのときは p/l/q を表します。
図 1 にファイル階層の例を示します。/tmp/bar というパスにあるシンボリックリンク 11 は ../gnu という相対パスを指していますが、このファイルはこの段階では存在していません。
一般的に、次の規則に従えばファイル階層の再帰的な探索は終了します:
. と .. を無視する。
シンボリックリンクをたどる場合には木ではなく一般のグラフを走査することになるので、たどったノードを覚えておかないとループを避けることができません。
それぞれのプロセスはワーキングディレクトリを持ちます。ワーキングディレクトリは getcwd 関数で取得することができ、chdir で変えることができます。chroot p を使えばファイル階層のビューを制限することができます。これによってディレクトリ p が制限されたビューのルートになります。それ以降は絶対パスが新しいルート p からのものとして解釈されます (新しいルートからの .. は p 自身になります)。
ファイルにアクセスする方法は二つあります。一つ目はファイルシステム階層の ファイル名 (あるいは パス名) を利用する方法です。ハードリンクがあるので、全てのファイルは複数のファイル名を持つことができます。ファイル名は string 型の値です。例えばシステムコール unlink, link, symlink そして rename はどれもファイル名を使います。
以下のような効果を持ちます:
unlink f はファイル f を削除する。 Unix コマンド rm -f f と同じ。
link f1 f2 は f2 という名前で f1 というファイルを指すハードリンクを作成する。Unix コマンド ln f1 f2 と同じ。
symlink f1 f2 は f2 という名前で f1 というファイルを指すシンボリックリンクを作成する。Unix コマンド ln -s f1 f2 と同じ。
rename f1 f2 はファイル f1 をファイル f2 にリネームする。Unix コマンド mv f1 f2 と同じ。
ファイルにアクセスする二つ目の方法はファイルディスクリプタを使うものです。ファイルディスクリプタはファイルへのポインタであり、ファイルの名前の他にも現在の読み込み/書き込み位置、アクセス権限 (読み込み/書き込みは可能か?)、入出力を管理するためのフラグ (ブロッキング/ノンブロッキングや上書き/追記など)といった情報を含みます。ファイルディスクリプタは抽象型 file_descr の値です。
ファイルへの名前を使ったアクセスはファイルディスクリプタを使ったアクセスと独立しています。例えばあるファイルのファイルディスクリプタを取得したとき、そのファイルを消去したりリネームしたりすることは可能ですが、そうした場合でもファイルディスクリプタは元のファイルを指したままです。
プログラムが実行されると 3 つのディスクリプタが確保され、Unix モジュールのstdin, stdout, stderr という変数に割り当てられます。
これらのディスクリプタはそれぞれプロセスの標準入力、標準出力、標準エラー出力に対応します。
プログラムがコマンドラインから実行されリダイレクトされることがない場合、三つのディスクリプタは端末を表します。しかし例えば入力がシェルの cmd < f を使ってリダイレクトされている場合、cmd を実行している間はディスクリプタ stdin は f というファイルを指します。同様に、 cmd > f と cmd 2> f はコマンドの実行中にそれぞれ stdout と stderr をファイル f に割り当てます。
システムコール stat, lstat および fstat はファイルについてのメタ属性、つまりそのファイルの内容についてではなくそのノード自身についての情報を返します。例えばファイルの識別子、ファイルの種類、アクセス権限、最終更新日時といった情報などが含まれます
システムコール stat と lstat はファイル名を引数として受け取りますが、fstat はそれまでに開かれたディスクリプタを受け取りそのディスクリプタが指しているファイルの情報を返します。stat と lstat はシンボリックリンクに対して異なった動作をします。lstat はシンボリックリンクそのものの情報を返しますが、stat はシンボリックリンクが指すファイルに関する情報を返します。これら 3 つのシステムコールの返り値は stats 型のレコードです。そのフィールドは図 1 に説明されています。
| フィールド名 | 説明 | ||||||||||||||
st_dev : int | ファイルが保存されているデバイスの ID を表す。 | ||||||||||||||
st_ino : int | パーティションにおけるファイルの ID (inode 番号と呼ばれます) を表す。(st_dev, st_ino) の組でファイルシステム内のファイルを識別できる。 | ||||||||||||||
st_kind : file_kind | ファイルの種類を表す。 file_kind 型は列挙型であり、以下のコンストラクタを持つ:
| ||||||||||||||
st_perm : int | ファイルへのアクセス権限を表す。 | ||||||||||||||
st_nlink : int | ファイルがディレクトリの場合はディレクトリ内の要素の数を表す。 ファイルがディレクトリ出ない場合、このファイルに対するハードリンクの数を表す。 | ||||||||||||||
st_uid : int | ファイルの所有ユーザを表す。 | ||||||||||||||
st_gid : int | ファイルの所有グループを表す。 | ||||||||||||||
st_rdev : int | ファイルが特殊ファイルの場合、ファイルに関連付けられた周辺機器の ID を表す。 | ||||||||||||||
st_size : int | ファイルのサイズ (バイト) を表す。 | ||||||||||||||
st_atime : int | ファイルが最後にアクセスされた時間を、 1970年1月1日深夜0時 gmt からの経過秒数で表す。 | ||||||||||||||
st_mtime : int | ファイルが最後に更新された日時を表す (単位は同上)。 | ||||||||||||||
st_ctime : int | ファイルの状態が最後に更新された日時を表す。ファイルへの書き込み、アクセス権限の変更、所有ユーザ/グループの変更、リンク数の変更などがファイルの状態を変化させる。
| ||||||||||||||
stats 構造体のフィールドファイルはデバイス番号 st_dev (大抵の場合はファイルのあるディスクパーティションの番号) とinode 番号 st_ino で一意に識別できます。
ファイルは所有者 st_uid と所有グループ st_gid を持ちます。マシン上の全てのユーザとグループは通常 /etc/passwd と /etc/gourps に保存されています。ユーザとグループを文字列からポータブルに検索するには getpwnam 関数と getgrnam 関数が使えるほか、getpwuid 関数と getgrgid 関数を使うと id から検索できます。
プロセスを実行しているユーザの名前とそのユーザが属している全てのグループ番号はそれぞれ getlogin と getgroups 関数で取得できます。
chown 関数はファイル (第一引数) の所有者 (第二引数) と所有グループ (第三引数) を変えます。ファイルディスクリプタを持っているならば、 代わりに fchown 関数が使えます。任意のファイルの所有者と所有グループを変更できる権限を持つのはスーパーユーザだけです。
プログラムの実効 uid がファイルと等しいとき、あるいは実効 gid または実効ユーザの属する補助グループの一つがファイルの所有グループと等しい場合は、特権無しで所有ユーザ/グループの変更が可能です。
アクセス権限は整数の中にビット列として格納されており、file_perm は int の別名に過ぎません。そこには所有ユーザ、所有グループおよびその他のユーザの読み込み、書き込みおよび実行のための権限を表すビットとスペシャルビットが保存されています:
| Special | User | Group | Other | ||||||||
| – | – | – | – | – | – | – | – | – | – | – | – |
OoSUGO
| |||||||||||
ここでユーザ (User) 、グループ (Group)、その他 (Other) というフィールドの中には、読み込み (r)、 書き込み (w) そして実行 (x) の権限がこの順番で保存されています。ファイルの権限はこれらの権限を合わせたものであり、例を表 2 に示します。
| ビット (8進表記) | ls -l の表記 | アクセス権限 |
0o100 | --x------ | 所有ユーザによって実行可能 |
0o200 | -w------- | 所有ユーザによって書き込み可能 |
0o400 | r-------- | 所有ユーザによって読み込み可能 |
0o10 | -----x--- | 所有グループのメンバーによって実行可能 |
0o20 | ----w---- | 所有グループのメンバーによって書き込み可能 |
0o40 | ---r---- | 所有グループのメンバーによって読み込み可能 |
0o1 | --------x | その他のユーザによって実行可能 |
0o2 | -------w- | その他のユーザによって書き込み可能 |
0o4 | ------r-- | その他のユーザによって読み込み可能 |
0o1000 | --------t | グループに対する t ビット (スティッキービット) |
0o2000 | -----s--- | グループに対する s ビット (SGID) |
0o4000 | --s------ | ユーザに対する s ビット (SUID) |
非ディレクトリファイルに対して、読み込み、書き込みおよび実行の権限が意味することは明らかです。ディレクトリに対する実行権限とはそのディレクトリに入る (chdir する) ための権限であり、読み込み権限とはディレクトリの内容を一覧で表示するための権限です。ただしディレクトリ内のファイルやサブディレクトリの名前を知っている場合、それらを読み込むためにはディレクトリの読み込み権限は必要ではありません。
スペシャルビットは x ビットが立っていない場合には意味を持ちません (x が 立っていないならば、追加の権限を与えません) 。スペシャルビットの場所が x と同じで、x が設定されていないときには s, t の代わりに S, T が使われるのはこのためです。
t フラグはスティッキービットと呼ばれ、このフラグが付いたディレクトリでは全てのユーザがファイルとディレクトリの作成を行えますが、削除が行えるのは所有者とルートだけです。
s ビットが立っている実行可能ファイルを実行すると、ファイルの所有者または所有グループとしてファイルが実行されます。さらにプログラムの実行時にシステムコール setuid と setgid を呼ぶことで、実効ユーザ識別子とグループを本来のユーザ/グループに切り変えることができます。
setuid と setgid が呼ばれたとき、プロセスは元のユーザ/グループ識別子を保存します。元の識別子が保存されるのは実効識別子を特別な権限なしに後で戻すことができるようにするためです。システムコール getuid と getgid は元の識別子を返し、geteuid と getegid は実効識別子を返します。
ただしスーパーユーザが setuid と setgid を実行した場合は別で、この場合は実効ユーザ/グループ識別子と実ユーザ/グループ識別子の両方を変更します。
プロセスは他にもファイル作成マスクを持ちます。これはファイル権限と同じようにエンコードされ、名前が示すように、禁止する操作を表します。ファイルを作成するとき、ファイル作成マスクで1になっているビットは作成されるファイルの権限では 0 になります。ファイル作成マスクはシステムコール umask で取得および変更できます。
システム変数を変更する多くのシステムコールと同じように、ファイル作成マスクを変更する umask は古い値を返します。そのため、この関数を二回呼べば現在の値を確認できます。一回目は適当な値を入力して変数の現在の値を手に入れ、二回目でその値を入力して変数を元の値に戻します。例えば:
ファイルアクセス権限はシステムコール chmod と fchmod で変更できます。
これらの関数が動作していることはシステムコール access によって “動的に” 確認できます。
ここでアクセスされるファイルへの権限の問い合わせは access_permission 型の値のリストで表されます。 F_OK はファイルが存在しているかどうかを (他の権限を確認せずに) 確認します。他の値の意味は明らかです。
access によって調べられる情報は lstat で得られる情報よりも制限的なことがあることに注意してください。これはファイルシステムが制限された権限 — 例えば、読み込み専用モード — のもとにマウントされる場合があるためです。動的な 情報 (プロセスが実際にできることへの制限) と 静的な 情報 (ファイルシステムが指定する制限) を区別したのはこのためです。
ディレクトリに書き込めるのカーネルだけ (そしてファイルを作成するときだけ) です。そのため、ディレクトリを書き込みモードで開くことは禁止されています。 Unix の特定のバージョンでは、読み込み専用モードでディレクトリを開いて readで読むことが許されていますが、別のバージョンでは禁止されています。しかしディレクトリエントリのフォーマットは Unix のバージョンによって異なり、複雑なことが多いので、仮にディレクトリへの書き込みができたとしても行うべきではありません。次の関数を使うとポータブルにディレクトリを走査することができます:
システムコール opendir はディレクトリのディレクトリディスクリプタを返します。 readdir はディスクリプタの次のエントリを読んで同じディレクトリ内のファイルの名前を返すか、ディレクトリの終端に到達した場合には End_of_file 例外を出します。rewinddir はディスクリプタをディレクトリの最初に移動し、closedir はディレクトリディスクリプタを閉じます。
Misc モジュールに含まれる次のライブラリ関数はディレクトリ dirname 内のエントリーについて、関数 f を繰り返し適用します。
ディレクトリの作成と空ディレクトリの削除には mkdir と rmdir を使います。
mkdir の第二引数には新しく作られるディレクトリのアクセス権限を指定します。すでに空であるディレクトリしか削除することはできません。そのためディレクトリとその要素を削除するにはまず再帰的にディレクリの要素を削除してからディレクトリを削除することが必要になります。
Unix コマンド find はファイル階層にあるファイルで一定の条件 (ファイル名、タイプ、権限など) に合致するものを一覧で表示します。このセクションではこの探索を実装したライブラリ関数 Findlib.find と、-follow そして -maxdepth オプションに対応した find コマンドを作成します。
Findlib.find に対するインターフェースを以下のように定めます:
関数呼び出し
はリスト roots で指定されるファイル (絶対パスまたは関数が呼ばれたときのプロセスのカレントディレクトリからの相対パス) をルートとするファイル階層を最大 depth の深さまで、 フラグ follow がセットされているならばシンボリックリンクをたどって探索します。 探索を開始したパスを r とすると、探索結果のパスは r を先頭に持ちます。探索で見つかったパス p は Unix.lstat p (follow が true の場合は Unix.stat p) の結果とともに action 関数に渡されます。ディレクトリに対しては、action 関数は探索をそのディレクトリの探索を続けるべきか (true) かやめるべきか (false) を返します。
handler 関数は探索中に起こった Unix_error 型のエラーを報告します。エラーが起こった場合は、例外の引数が handler 関数に渡され探索は続行されます。例外が action 関数または handler 関数の内部で起こった場合にはその時点で探索は終了し、例外は呼び出し側に伝わります。action と handler の中で出される Unix_error 例外を探索中に起こったエラーと区別するために、Hidden 例外でラップします (hide_exn と reveal_exn 参照)。
ディレクトリはデバイス番号と inode 番号の組 id によって識別されます ( 12 行目)。リスト visiting がそれまでに訪問したディレクトリを記録します。この情報が必要になるのはシンボリックリンクをたどる時だけです ( 21 行目)。
ここまでくれば、 find コマンドを作るのは簡単です。このコードの主な処理は Arg モジュールを使ってコマンドライン引数をパースすることです。
この find の機能は少ないですが、これからの練習問題で示されるように、ライブラリ関数 FindLib.find ははるかに多機能です。
Findlib.find を使って、以下の Unix コマンドと同じコマンド find_out_CVS を書いてください。
このコマンドはカレントディレクトリから始まりファイルの名前を再帰的に表示しますが、CVS という名前のディレクトリについては表示することもディレクトリに入ることもしません。
解答
getcwd 関数はシステムコールではありませんが、 Unix モジュールで定義されています。getcwd の “原始的な” 実装を与えてください。まずアルゴリズムの原理を言葉で説明してから実装するようにしてください (同じシステムコールを何度も呼ぶのは避けたほうが良いでしょう)。
解答
openfile 関数を使うと指定した名前のファイルに対するディスクリプタを得ることができます (対応するシステムコールは open ですが、これは ocaml の予約語なので使うことができません) 。
第一引数は開くファイルの名前です。第二引数は open_flag 列挙型のフラグのリストであり、ファイルが開かれるモードおよびファイルが存在しなかったときの動作を指定します。file_perm 型の第三引数はファイルが作られるときのファイルのアクセス権限を指定します。返り値はファイルへのディスクリプタであり、入出力位置は最初ファイルの先頭にあります。
第二引数のフラグのリストは以下のうちちょうど一つだけを含む必要があります。
O_RDONLY | 読み込み専用モードで開く。 |
O_WRONLY | 書き込み専用モードで開く。 |
O_RDWR | 読み込み/書き込みモードで開く。 |
これらのフラグは読み込みと書き込み命令がディスクリプタに対して行えるかどうかを指定します。読み込み/書き込み権限のないファイルを読み込み/書き込みモードで開こうとした場合、openfile は失敗します。このため、全てのファイルを O_RDWR を使って開こうとするのは避けるべきです。
openfile の第二引数のフラグには以下の値を一つ以上含むことができます。
O_APPEND | 追記モードで開く。 |
O_CREAT | ファイルが存在しない場合作成する。 |
O_TRUNC | ファイルが存在する場合、内容を切り捨てる。 |
O_EXCL | ファイルがすでに存在しているなら失敗する。 |
O_NONBLOCK | ノンブロッキングモードで開く。 |
O_NOCTTY | 端末モードでは機能しない。 |
O_SYNC | ファイルに関する同期モードで書き込みを行う。 |
O_DSYNC | データに関する同期モードで書き込みを行う。 |
O_RSYN | 同期モードで読み込みを行う。 |
最初のグループはファイルが存在に関連した動作を決めます:
O_APPEND が指定された場合、全ての書き込み処理の前に入出力位置がファイルの末尾にセットされる。これによって書き込まれたデータはファイルの末尾に付け足されるようになる。O_APPEND が無い場合、書き込みは入出力位置 (初期位置はファイルの先頭) で行われる。O_TRUNC が指定された場合、ファイルは開かれたときに切り捨てられる。ファイルの内容は失われてファイルの長さは 0 になり、最初の書き込みは空ファイルに行われる。O_TRUNC が無い場合、書き込みはファイルの先頭からそこにあるデータを上書きしながら行われる。O_CREAT が指定された場合、ファイルが存在しなければ作成される。作成されるファイルは空で、その権限は openfile の第三引数とプロセスの作成マスクによって決まる (作成マスクは umask によって取得および確認できる) 。O_EXCL が指定された場合、ファイルがすでに存在しているなら openfile は失敗する。このフラグと O_CREATE を併せると、ファイルを ロック1 として使うことができる。ロックを取得したいプロセスは O_EXCL と O_CREAT を指定して openfile を呼ぶ。ファイルが存在していた場合、これは他のプロセスがロックを取得済みであることを意味し、openfile はエラーを出す。ファイルが存在せず openfile がエラーを出さずに値を返しファイルが作られた場合、他のプロセスはロックを取得することができなくなる。ロックを開放するにはプロセスはロックファイルに unlink を行う。ファイルの作成はアトミックな演算である: もし二つのプロセスが O_EXCL と O_CREAT を指定して同時に同じファイルを作成しようとした場合、多くとも一つのプロセスしか成功しない。この手法の欠点はプロセスが現在使用中のロックを得るためにビジーウェイトする必要があることと、プロセスの異常終了がロックを開放しない場合があることである。
たいていのプログラムは openfile の第三引数として 0o666 を使います。これは文字列でいうと rw-rw-rw- を意味します。デフォルトファイル作成マスクが 0o022 の場合、ファイルは rw-r--r-- の権限で作成されます。マスクがより寛大で 0o002 の場合には、ファイルは rw-rw-r-- の権限で作成されます。
ファイルから読み込むには以下のようにします:
O_CREAT が指定されていないならば、第三引数は何でも構いません。 0 がよく使われます。
それまでの内容にかかわらず空ファイルに書き込むには以下のようにします:
ファイルが実行可能なコード (例えば ld によって作られるファイルやスクリプトなど) を含む場合、ファイルを実行権限付きで作成します:
ファイルが機密情報 (例えば mail が既読メールを保存する “メールボックス”) である場合、書き込み権限を所有ユーザのみとして作成します:
存在するファイルの末尾にデータを付け足すか、ファイルが存在しない場合には作成するには以下のようにします:
O_NONBLOCK フラグはファイルが名前付きパイプまたはスペシャルファイルの場合に、ファイルのオープンとその後の読み込みがノンブロッキングであることを保証します。
O_NOCTYY フラグはファイルが制御端末 (キーボードやウィンドウなど) の場合に、そのファイルが呼び出しプロセスの制御端末にならないことを保証します。
フラグの最後のグループは読み込みと書き込み処理をどのように同期するかを指定します。デフォルトでは処理は同期しません。
O_DSYNC が指定された場合、データの書き込みは同期されプロセスは全ての書き込みが物理的にメディア (通常はディスク) に行われるまでブロックされる。
O_SYNC が指定された場合、ファイルのデータとメタ属性の書き込みが同期される。
O_RSYNC が O_DSYNC と共に指定された場合データの読み込みも同期される: 読み込みが起こる前にそれまでの全ての書き込み (要求されたが実行されていないものを含む) が本当にメディアに書き込まれることが保証される。O_RSYNC が O_SYNC と共に指定された場合上記のことがメタ情報にも適用される。
システムコール read と write はバイト列をファイルに書き込みます。歴史的な理由から、システムコール write は OCamlでは single_write という名前です。
二つの関数 read と single_write は同じインターフェースを持ちます。第一引数は操作を行うファイルディスクリプタです。第二引数2は read の場合は読み込んだバイト列を収める文字列で、single_write の場合は書き込むバイト列です。第三引数は文字列の中で入出力を行う最初のバイトの位置で、第四引数は入出力を行うバイト数です。第三、四引数は第二引数の部分文字列を定めています (この部分文字列はもちろん有効なものである必要がありますが、read と single_write はこのことをチェックしません) 。
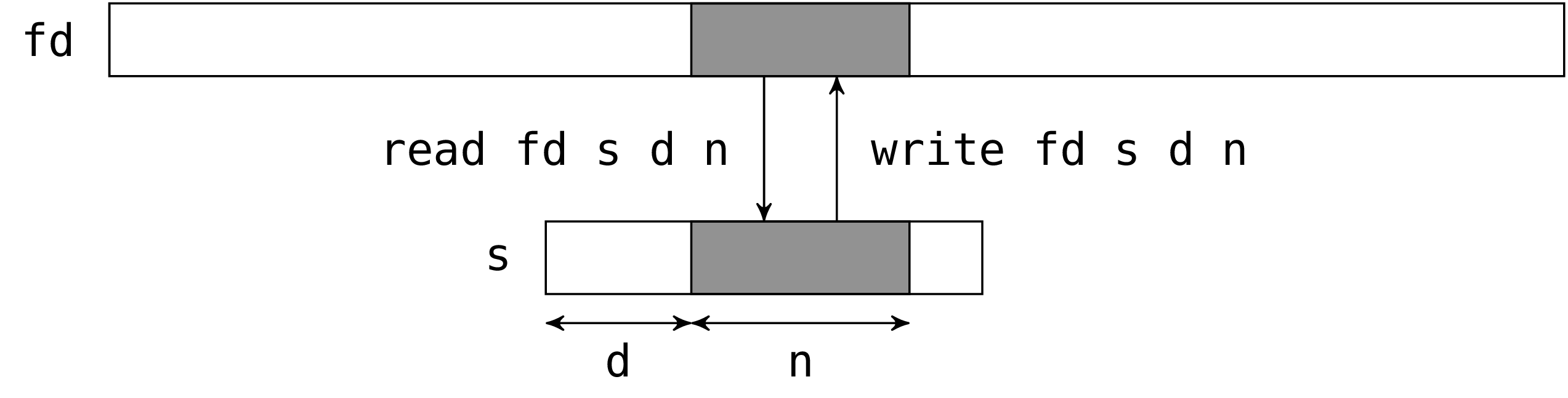
read と single_write は実際に読み込んだ/書き込んだバイト数を返します。
入出力の命令はファイルディスクリプタの現在の入出力位置から行われます (ファイルが O_APPEND モードで開かれた場合、この位置は書き込み命令の前にファイルの末尾にセットされます)。システムコールの後、現在位置は読み込み/書き込みを行ったバイト数だけ進みます。
書き込みでは実際に書き込むバイト数は要求されたバイト数と普通一致しますが、いくつか例外があります: (i) バイト列を書き込めなかった場合 (例えばディスクが満杯なとき) (ii) ディスクリプタがノンブロッキングモードで開かれたパイプまたはソケットな場合 (iii) 書き込む文字列が OCamlの持つバッファより大きい場合
(iii) の理由は OCamlが最大値の制限された補助バッファを使っているためです。バッファの最大値よりも書き込みが大きかった場合、書き込みは部分的になります。この問題を解決するために、 OCamlには エラーが出るか全てのデータが書き込まれるまで書き込みを繰り返す write があります。しかしこの関数を使うとエラーが起こった場合に書き込まれたバイト数を知ることができません。single_writeを使うと書き込みの原始的になり(何が書き込まれたかが分かる)、オリジナルの Unix システムコールにより忠実になるので single_write を使うべきです。single_write の実装はセクション 5.7 で説明されています。
fd が書き込み専用モードで開かれたディスクリプタだとします。
は "lo worl" という文字列を対応するファイルに書き込み、 7 を返します。
読み込みでは実際に読み込んだバイト数が読むように要求されたバイト数よりも小さいことがありえます。例えばファイルの終端が近いときは現在位置からファイルの終端までのバイト数が要求されたバイト数よりも小さくなります。特に現在位置がファイルの終端なとき read は 0 を返します。“ゼロはファイルの終端と等しい” という慣習はスペシャルファイルやパイプ、ソケットに対しても成り立ちます。例えば ctrl-D を端末に入力すると read は 0 を返します。
read が要求した値よりも小さい値を返すもうひとつの例は端末から読み込む場合です。この場合 read はまず行の入力が利用可能になるまでブロックします。行が入力され、その長さが要求されたバイト数よりも短い場合、read は要求されたバイト数に達しようと次のデータを待つことをせずに行の入力が利用可能になった時点で値を返します(これは端末のデフォルトの動作ですが、文字ごとに読み込むように変えることもできます。セクション section 2.13 と terminal_io 型を参考にしてください)。
次のプログラムは標準入力から最大 100 文字を読み込み、文字列として返します。
以下の関数 really_read は read と同じインターフェースを持ちますが、要求されたバイト数を取得するために追加の読み込みを行います。読み込み中にファイルの終端に達した場合には End_of_file 例外が出ます。
システムコール close はファイルディスクリプタを閉じます。
ディスクリプタが閉じられると読み込みや書き込みなどのディスクリプタに関する操作は全て失敗します。ディスクリプタは必要なくなった時点で閉じられるべきですが、閉じることは必須ではありません。write 関数による書き込みの要求が即時にカーネルに伝わるために、Pervasives モジュールのチャンネルとは違って全ての書き込みが実行されたことを保証するためにチャンネルを閉じる必要はありません。一方プロセスが確保できるディスクリプタの数はカーネルによって (数百から数千に) 制限されていることから、使わないディスクリプタを close で開放しないとディスクリプタが枯渇します。
引数として与えられる f1 と f2 について、f1 のバイト列を f2 にコピーするコマンド file_copy を作ります。
作業の多くは file_copy 関数によって実行されます。最初に入力ファイルのディスクリプタを読み込み専用で開き、次に出力ファイルのディスクリプタを書き込み専用モードで開きます。
出力ファイルがすでに存在している場合ファイルは切り捨てられ (O_TRUNC オプション)、存在しない場合には作成されます (O_CREAT オプション)。作成されるファイルの権限は rw-rw-rw- をファイル作成マスクで改変したものですが、これは十分ではありません。実行可能ファイルをコピーする場合は、コピー先も実行可能であるべきだからです。コピー先のファイルと元のファイルの権限を同じにする方法は後述します。
copy_loop 関数の中で buffer_size バイトのコピーを行います。まずbuffer_size の読み込みを行い、これが 0 を返した場合はファイルの終端に到達しているのでコピーを終了します。そうでなければ読み込んだ r バイトを出力ファイルに書き込んで同じことを繰り返します。
最後に二つのディスクリプタを閉めます。プログラム本体となる copy はコマンドが二つの引数を受け取ったことを確認し、その引数を file_copy 関数に渡します。
コピー中に起きた Unix_error はhandle_unix_error によって補足され、エラーの内容が表示されます。ここで起こるエラーの例としては入力ファイルが存在しないために開くことができない、権限が足りなくてファイルを開くことができない、ディスクに容量がなくて書き込むことができない、などがあります。
file_copy の例では読み込みを 8192 バイトごとに行ないました。どうして 1 バイトごとや 1 メガバイトごとに読み込みをしないのでしょうか? 理由は効率です。
図 2 に file_copy の速度を示します。一秒間にコピーできるバイト数を縦軸に、ブロックサイズ (buffer_size の値) を横軸に示しています。
転送されるデータの総量はブロックサイズに関わらず一定です。ブロックサイズが小さい時は、コピー速度はブロックサイズにほぼ比例しています。実行時間の多くがはデータの転送ではなく、copy_loop のループと read と write の呼び出しに使われているということがわかります。更に詳細に実行時間を計測すると、ほとんどが read と write の呼び出しに使われていることがわかります。システムコールは処理が大きくない場合でも (テストに使われた PC — 2.8 GHz Pentium 4 — では) 最低 4 マイクロ秒、一般的には 1 から 10 マイクロ秒程度かかります。そのため入出力のブロックサイズが小さい場合にはシステムコールの時間が支配的になります。
ブロックが大きくて 4KB から 1MB の場合、コピー速度は最大値で一定です。ここではシステムコールとループにかかる時間がデータ転送にかかる時間に比べて小さくなっているということです。加えてバッファのサイズがシステムのキャッシュよりも大きくなるためにデータの転送がシステムコールのコストを上回るようになります3。
最後に、ブロックがとても大きい (8 MB 以上) ときにはコピー速度は最大値よりも少しだけ小さくなります。ここで影響するのはブロックを確保してメモリのページを割り当てるのを書き込み中に行う時間です。
以上のことから学べることは、システムコールはほとんど何も処理をしていない場合でも大きな — 通常の関数呼び出しよりもはるかに大きな — コストがかかるということです。アーキテクチャによって違いますが、だいたい 2 から 20 マイクロ秒が呼び出しごとにかかります。そのためシステムコールの数を減らすことが重要になります。読み込みと書き込みに関して言えば、一文字ごとではなくある程度のサイズのブロックごとに行われるべきです。
file_copy の例では大きなブロックで入出力を行うのは難しくありません。しかしある種のプログラムでは一文字ごとに入出力を行うことが自然なことがあります(例えばファイルから一行ずつ読む処理、字句解析、数字の印字など)。このようなプログラムのために、ほとんどのシステムにはアプリケーションとオペレーティングシステムの間にソフトウェアのレイヤーを追加する入出力ライブラリがあります。例えば OCamlには Pervasives モジュールにファイルディスクリプタと似た抽象型in_channel と out_channel が定義されていて、この型に関する関数 input_char,input_line、output_char あるいは output_string があります。このレイヤーはバッファを使って複数回の一文字ごとの読み込みと書き込みを一回のシステムコールにまとめます。これによって一文字ごとに処理をするプログラムの効率が良くなります。さらにこのレイヤーによってプログラムがよりポータブルになります。Pervasives モジュールを使うプログラムを新しいオペレーティングシステムに移植するには、このライブラリをそのシステム上で使えるシステムコールを使って実装すれば良いからです。
バッファを使った入出力のテクニックの例として、OCamlの Pervasives ライブラリの一部を実装します。 次のようなインタフェースを持ちます:
“読み込み” の部分から始めます。
抽象型 in_channel は次のように定義します:
文字列 in_buffer は文字通りのバッファです。フィールド in_fd は読み込むファイルに開かれた (Unix の) ファイルディスクリプタです。フィールド in_pos は読み込みの現在位置を示します。フィールド in_end は事前にバッファへ読み込まれた文字列のうち有効な部分長さです。
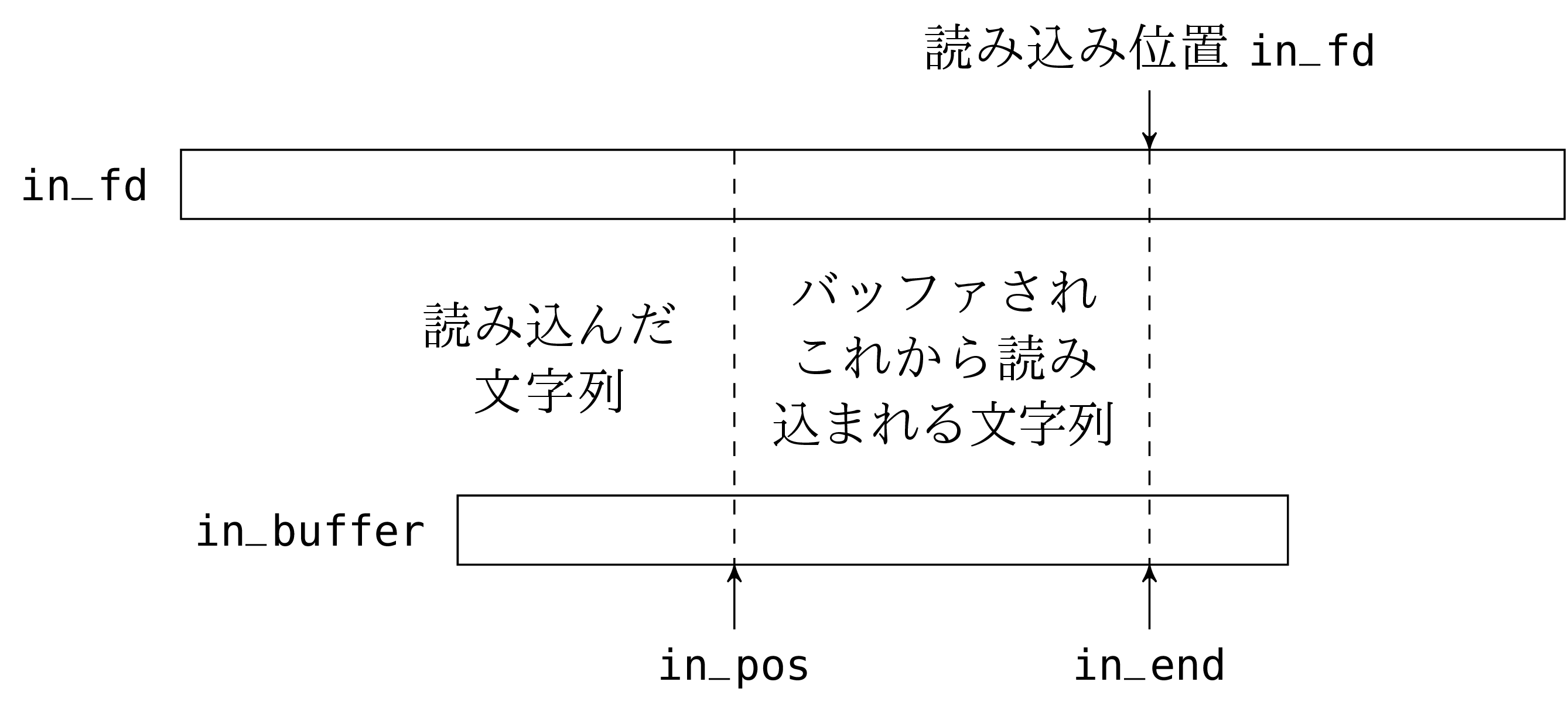
in_pos と in_end のフィールドは読み込み処理中に更新されるので mutable として宣言します。
読み込みのためにファイルを開いたとき、同時に合理的なサイズの (システムコールが多くなりすぎない程度に大きく、メモリを無駄遣いしない程度に小さい) バッファを作ります。その後 in_fd フィールドを読み込み専用で開いたファイルに対する Unix のファイルディスクリプタで初期化します。バッファは最初空です (ファイルからのどんな文字列も含んでいません) 。そのため in_end フィールドは 0 で初期化します。
in_channel から文字を読むとき、次の二つのうち一つを行います。一つ目はバッファに一つ以上まだ読んでいない文字がある、つまり in_pos フィールドの値が in_end フィールドの値よりも小さい場合です。このときはバッファの in_pos にある文字を返し、 in_pos をインクリメントします。もう一つはバッファが空の場合で、このときは read を呼んでバッファにもう一度文字列を読み込みます。read が 0 を返したならファイルの終端に達したということなので End_of_file 例外を出します。そうでなければ in_end に呼んだ文字の数を代入します。
in_channel を閉じる処理は対応する Unix のファイルディスクリプタを閉じるだけです。
“書き込み” の部分は “読み込み” の部分にとても良く似ています。唯一異なるのはバッファがまだ読んでいない読み込み (バッファされたが読み込まれていない文字列) を保持するのではなくて、まだ完了していない書き込み (バッファされたがファイルディスクリプタに書き込まれていない文字列) を保持する点です。
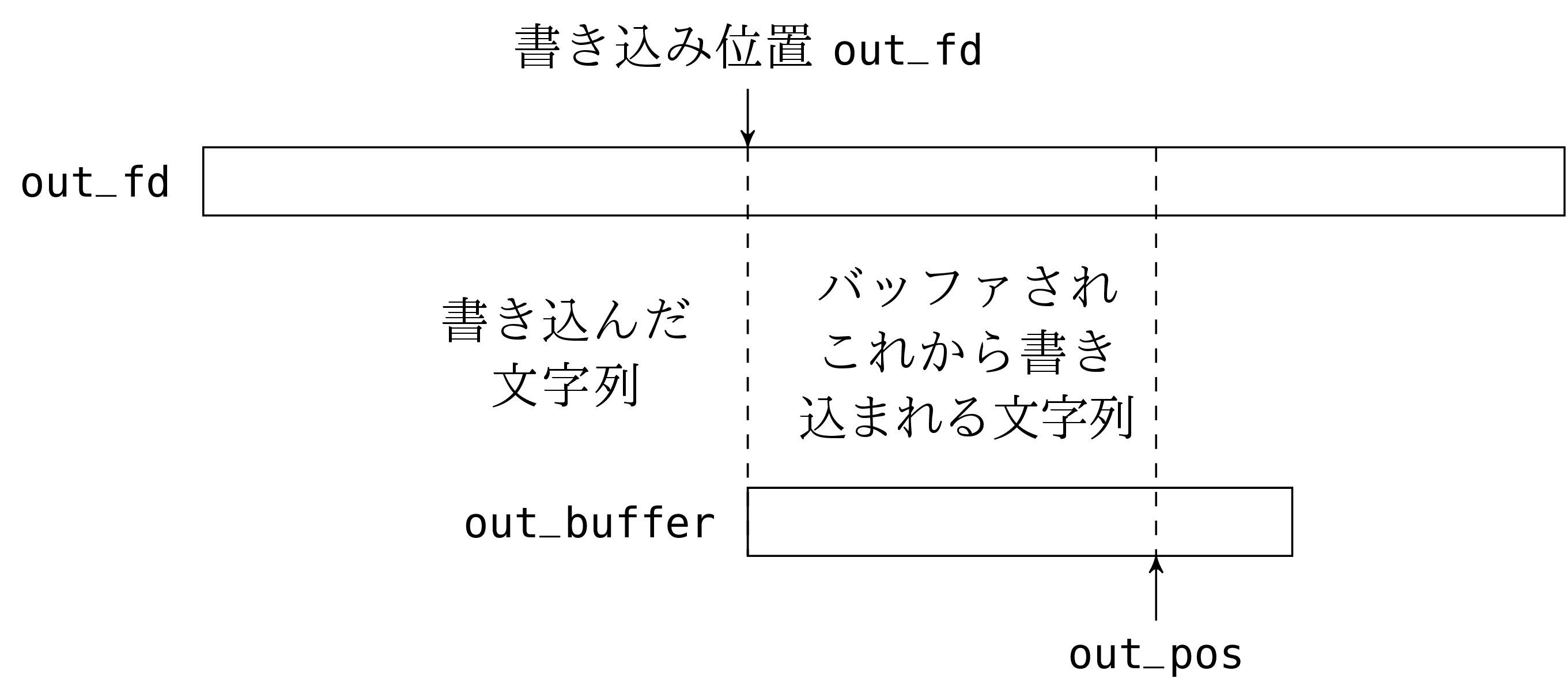
out_channel に文字を書き込むには次の二つのうち一つを行います。一つ目はバッファが満杯ではない場合で、このときは文字をバッファを out_pos の位置に保存して out_pos をインクリメントします。もう一つはバッファが満杯の場合で、このときは write を呼んでバッファを空にしてからバッファの先頭に文字を読み込みます。
out_channel を閉めるときにはバッファの内容 (位置 0 から out_pos - 1 までの文字列) を書き込むことを忘れないでください。これを忘れると最後にバッファが空になってからチャンネルに書き込まれた内容が失われます。
この関数は output_char をそれぞれの文字に対して複数回呼んだときと同じ動作をしますが、より効率的です。
解答
システムコール seek はファイルディスクリプタの現在の入出力位置を変更します。
第一引数はファイルディスクリプタで第二引数は移動させる位置です。第二引数は seek_command 型の第三引数に基づいて解釈されます。この列挙型は位置の種類を指定します:
SEEK_SET | 第二引数は関数を呼び出した後の入出力位置を表す。ファイルの最初の文字は位置 0 である。 |
SEEK_CUR | 第二引数は現在の入出力位置からの相対的なオフセットを表す。正の値のとき前に、負の値のとき後ろに動く。 |
SEEK_END | 第二引数はファイルの終端からの相対的なオフセットを表す。SEEK_CUR と同様にオフセットは正負どちらにもなれる。
|
lseek の返り値は関数を実行した後の入出力位置 (絶対位置) です。
負の絶対位置が指定された場合はエラーとなります。ファイルの終端よりも後ろの位置を指定することは可能です。このとき read は (ファイルの末尾に達しているので) 0 を返し、write はまずファイルの終端から入出力位置まで 0 を書き込んでからデータを書き込みます。
カーソルを 1000 番目の文字に移動させるには以下のようにします:
一文字巻き戻すには以下のようにします:
ファイルのサイズを求めるには以下のようにします:
ファイルディスクリプタが O_APPEND モードで開かれている場合、入出力位置は毎回の書き込みの前にファイルの終端にセットされます。そのため書き込み位置を指定するために lseek を読んでも意味がありません。一方読み込みを指定することには使えます。
コミュニケーションデバイス (パイプ、ソケット) や端末を始めとする多くのスペシャルファイルなどの、入出力の絶対位置が意味を持たないタイプのファイルについては lseek の動作は未定義です。Unix のほとんどの実装ではこれらのファイルに対する lseek は無視されます (入出力位置はセットされますが、入出力処理は入出力位置を無視します)。いくつかの実装ではパイプとソケットに対する lseek はエラーを出します。
tail コマンドはファイルの末尾 n 行を表示します。tail を通常ファイルに対して効率よく実装するにはどうすればよいでしょうか ? -f オプションはどのすれば実装できるでしょうか (参考: man tail) ?
解答
Unix ではデータのやり取りはディスクリプタを通して行われ、ディスクリプタは永続性のファイル (通常ファイル、周辺機器) または揮発性のファイル (パイプとソケット、 5 章と 6 章参照) を表します。ファイルディスクリプタはデータのやり取りのための統一されたメディアによらないインタフェースを提供します。もちろんファイルディスクリプタに対する操作の実際の実装は背後にあるメディアによって異なります。
しかしあるメディアの全ての機能を使う必要がある場合は他のファイルと同じように扱うことはできません。ファイルのオープンや読み込み、書き込みなどの一般的な操作はほとんどのディスクリプタで同じ動作をします。しかしこのような一般的な操作であっても、周辺機器とパラメータで決まるアドホックな動作をするスペシャルファイルが存在します。またあるメディアに対してだけ可能な操作もあります。
システムコール truncate と ftruncate を使うと通常ファイルを短くすることができます。
第一引数は切り捨てるファイルで第二引数は切り捨てた後のサイズです。これより後ろの位置にある全てのデータは失われます。
シンボリックリンクに対するほとんどの操作はリンクを “たどり” ます。つまり、操作はリンクそのものではなくリンクが指すファイルに適用されます (例えば openfile, stat, truncate, opendir などはこのような動作をします) 。
二つのシステムコール symlink と readlink はシンボリックリンクそのものを操作します。
symlink f1 f2 は f1 へのシンボリックリンク f2 を作成します (Unix コマンド ln -s f1 f2 と同様です) 。readlink はシンボリックリンクの内容、つまりリンクが指すファイルの名前を返します。
スペシャルファイルは “キャラクタ” または “ブロック” に分類されます。前者は文字のストリームです。つまり文字の入出力は逐次的にしか行うことができません。例として端末やサウンドデバイス、プリンターなどがあります。後者は永続的な媒体を持つものであり、ディスクが典型です。文字はブロック単位で読み込むことができ、現在位置からの相対位置にシークすることができます。
スペシャルファイルは以下のように分類できます:
/dev/null | あらゆるものを飲み込み何も出てこないブラックホール。 プロセスの出力を /dev/null にリダイレクトすることでプロセスの出力を無視できる。 |
/dev/tty* | 制御端末。 |
/dev/pty* | 本物の端末ではないが端末をシミュレートし同じインターフェースを持つ擬似端末。 |
/dev/hd* | ディスク。 |
/proc | システム変数。 Linux ではシステム変数はファイルシステムで管理され、入出力が許されている。 |
多くのファイルに対するシステムコールはスペシャルファイルに対して違った動作をします。しかし read と write に関しては、ほとんどのスペシャルファイル (端末、テープドライバ、ディスクなど) が通常ファイルと同じ動作をします (読み書きするバイト数に制限があることがあります)。ただしそのようなスペシャルファイルの多くが lseek を無視します。
通常のファイルシステムに加えて、周辺機器を表すスペシャルファイルは動的に制御また設定される必要があります。例えばテープドライブには巻き戻しや早送りが、端末には行の編集モードや特殊文字による制御、シリアル通信用変数 (スピード、パリティなど) があります。Unix ではこれらデバイスのパラメータの設定は全てシステムコール ioctl を通して行います。しかし OCamlにはこのシステムコールが提供されていません。ioctl は引数の形が特殊なので統一的に扱うことができないためです。
端末と擬似端末はキャラクタタイプのスペシャルファイルで、 OCamlから設定を変更することができます。システムコール tcgetattr はオープンされたスペシャルファイルのファイルディスクリプタを受け取り posix 規格に基づいて端末の状態を表す terminal_io 型の構造体を返します。
この構造体を変更してシステムコール tcsetattr を呼ぶことで周辺機器の設定を変更できます。
第一引数は操作する周辺機器のファイルディスクリプタです。最後の引数は terminal_io 型の構造体で、周辺機器への引数となります。第二引数は変更がいつ起きるべきかを指定する setattr_when 列挙型の値です。即時 (TCSANOW)、 データを全て送ってから (TCSADRAIN)、 データを全て受け取ってから (TCAFLUSH) の三つを指定できます。書き込みに関するパラメータを変更するときには TCSADRAIN が、読み込みに関するパラメータを変更するときには TCSAFLUSH が推奨されます。
標準入力が端末または擬似端末の場合、パスワードを読む処理を行っている間はユーザが打ち込んだ文字列を表示するべきではありません。この処理は以下のように実装できます:
read_passwd 関数は stdin につながっている端末の現在の設定を取得するところから始まります。その後文字を表示しないように変更した設定を定義します。もしこの処理が失敗した場合標準入力は制御端末ではないので普通に一行の入力を受け取ります。そうでなければメッセージを表示し、端末の設定を変え、パスワードを読み込み、端末の設定を元に戻します。読み込みが失敗した後でも端末の設定が元に戻るように注意が必要です。
プログラムが別のプログラムを起動しその標準入力を端末 (もしくは擬似端末) につなげる必要がある場合があります。OCamlはこれをサポートしていません4。そのため擬似端末 (一般に /dev/tty[a-z][a-f0-9] という名前のついたファイル) の中からすでに開いているものを手動で探す必要があります。そしてその擬似端末のファイルをオープンすれば、新しいプログラムを標準入力がこのファイルになった状態で始めることができます。
端末のデータの流れを制御する関数が 4 つあります (割り込みを送る、送信の終了を待つ、待っているデータをフラッシュする、やり取りを再開する)。
tcsendbreak 関数は周辺機器に割り込みを送ります。第二引数は割り込みの長さです (0 は周辺機器のデフォルト値と解釈されます)。
tcdrain 関数は全ての書き込みデータが送信されるのを待ちます。
第二引数の値にもとづいて、 tcflush 関数は書き込まれたが送信されていないデータ (TCIFLUSH) か受け取ったが読み込まれていないデータ (TCOFLUSH) 、あるいはその両方 (TCIOFLUSH) を捨てます。
第二引数の値にもとづいて、 tcflow 関数はデータの送信を止める (TCOOFF) か、データの送信を再開する (TCOON) か、制御文字 stop あるいは start を送って送信を止める (TCIOFF) かをします。
setsid 関数はプロセスを新しいセッションに移し端末から切り離します。
二つのプロセスは同じファイルに同時に書き込むことができますが、書き込みが衝突した場合データの一貫性が失われることがあります。O_APPEND を使って常にファイルの末尾に書き込むようにしてこれを回避できることがあります。log ファイルにはこの方法で良いですが、データベースのように任意の場所に書き込みが起こるときは上手くいきません。そのような場合にはファイルを使うプロセスは他人のつま先を踏まないように協調する必要があります。ファイル全体に対するロックは補助ファイルを使うことで実装できます (?? ページ参照) が、システムコール lockf を使うとファイルの一部分をロックするより良い同期パターンを利用できます。
file_copy (セクション 2.9) を拡張して通常ファイルだけではなくシンボリックリンクとディレクトリにも対応させます。ディレクトリについてはその中身も再帰的にコピーすることにします。
通常ファイルのコピーにはすでに定義した 2.9 関数を再利用します。
次の set_infos 関数はファイルの所有者とアクセス権限、最終アクセス/変更日時を変更します。コピー先のファイルの情報をコピー元と同じにするためにこの関数を使います。
システムコール utime は最終アクセス/更新日時を、chmod と chownがアクセス権限と所有者を変更します。通常ユーザが chown を実行すると “permission denied” エラーが出て失敗することがありますが、このエラーは捕捉した上で無視します。
処理の本体である再帰関数は以下のようになります:
source ファイルの情報を読むところから処理が始まります。ファイルが通常ファイルの場合、 file_copy によってデータを、 set_infos によって情報をコピーします。ファイルがシンボリックリンクの場合、リンクがどこを指しているを読み取りそのファイルを指すリンクを作成します。ファイルがディレクトリの場合、目的となるディレクトリを作成しディレクトリのエントリを読み、各エントリに対して再帰的に copy\_rec を呼び出します。このときディレクトリそのものと親ディレクトリのエントリは無視します。これ以外のファイルについては警告を出して無視します。
メインプログラムは単純です:
ハードリンクを賢くコピーしてください。同じファイルが n 個の異なる場所に存在する場合、上記のプログラムではcopy_rec は同じファイルを n 個作成します。このような状況を検出し、コピーを一度だけして他の場所にはハードリンクを作るようにしてください。
解答
tar ファイルフォーマット (tape archive の略です) はファイル階層を一つのファイルに保存します。tar ファイルは小さなファイルシステムと見ることができます。
このセクションでは tar ファイルを読み書きする関数を定義します。そのほかに readtar という、 readtar a でアーカイブ a に含まれるファイルを表示し、readtar a f でアーカイブ a に含まれるファイル f を取り出すコマンドも作ります。ファイル階層全体を取り出すこととファイル階層からアーカイブを作ることは練習問題として読者に残します。
tar アーカイブは複数のレコードから成ります。それぞれのレコードがファイルを表します。レコードはファイルについての情報 (名前、種類、サイズ、所有者など) をエンコードするヘッダから始まり、ファイルの内容がその後に続きます。ヘッダは 512 バイトのブロックで、表 3 のような構造をしています。
| オフセット | 長さ | コードの種類 | 名前 | 説明 |
| 0 | 100 | 文字列 | name | ファイルの名前 |
| 100 | 8 | 8進 | perm | ファイルの権限 |
| 108 | 8 | 8進 | uid | 所有ユーザの ID |
| 116 | 8 | 8進 | gid | 所有グループの ID |
| 124 | 12 | 8進 | size | ファイルのサイズ (単位はバイト) |
| 136 | 12 | 8進 | mtime | 最終更新日 |
| 148 | 8 | 8進 | checksum | ヘッダのチェックサム |
| 156 | 1 | 文字 | kind | ファイルの種類 |
| 157 | 100 | 8進 | link | リンク |
| 257 | 8 | 文字列 | magic | シグネチャ ("ustar\032\032\0") |
| 265 | 32 | 文字列 | user | 所有ユーザの名前 |
| 297 | 32 | 文字列 | group | 所有グループの名前 |
| 329 | 8 | 8進 | major | 周辺機器のメジャー番号 |
| 337 | 8 | 8進 | minor | 周辺機器のマイナー番号 |
| 345 | 167 | パディング | ||
'\000' で終わる文字列でエンコードされるが、フィールド kind と size については終端の '\000' は無くても良い。
ファイルの内容はヘッダのすぐ後ろに保存され、サイズは 512 バイトの倍数まで 0 で拡張されます。レコードの後には別のレコードが続きます。ファイルは最低 20 ブロック (1 ブロックは 512 バイト) を持つように空のブロックでパディングされます。
tar アーカイブは脆い媒体に保存されて何年もしてから読み込まれることを想定しているので、ヘッダが傷ついたことを検出するための checksum フィールドがあります。その値はヘッダ内の全てのバイトの和です (チェックサムを計算するときには checksum フィールド自身は 0 として計算します)。
ヘッダの kind フィールドはファイルの種類を以下のように 1 バイトにエンコードします5:
'\0' or '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' |
REG | LINK | LNK | CHR | BLK | DIR | FIFO | CONT
|
ほとんどの場合 kind フィールドの値は stats 構造体の st_kind フィールドに保存されているUnix のファイルの種類 file_kind に対応します。LINK はアーカイブに保存されたファイルに対するハードリンクを表します。CONT はメモリの連続した領域に保存された通常ファイルを表します (これはいくつかのファイルシステムが持つ機能であり、通常ファイルと同じように扱うことができます)。
ヘッダの kind フィールドが LINK または LNK のとき、 link フィールドにはリンクの指す先のファイル名が保存されます。kind フィールドが CHR または BLK のとき、major と minor フィールドには周辺機器のメジャー番号とマイナー番号が保存されます。これらのフィールドはそれ以外のとき使用されません。
kind フィールドの値はヴァリアント型によって、 ヘッダはレコードによって自然に表現されます。
ヘッダの読み込みはあまり面白い処理ではありませんが、無視することもできません。
アーカイブの終端は本来なら新しいレコードが始まるべき場所にあるファイルの終端か、完全で空のブロックです。そのためヘッダを読み込むときに読むブロックは空なものか完全なものです。そこで really_read を再利用します。アーカイブが壊れていない限り、1 ブロックを読み込もうとしたときにファイルの終端を読むことはありません。
アーカイブに操作を行うには、操作の対象を見つけるまでレコードを順に読んでいく必要があります。通常はそれぞれのレコードのヘッダだけを読みこむだけですみますが、前に読み込んだアーカイブに戻ってその内容を読む必要があることもあります。そのような場合のためにそれぞれのレコードごとにそのヘッダとアーカイブ内の位置を記録しておきます。
アーカイブのレコード (ファイルの内容は除く) を読み込んで記録する一般的なイテレータを定義します。イテレータを一般的にするために、蓄積のための関数 f は抽象的なものにしておきます。こうすることでレコードの表示や破壊などの処理にも同じイテレータ関数を使うことができます。
fold_aux 関数は処理を offset の位置から開始し、 accu の中に途中経過が含まれています。レコードが始まる位置 offset まで移動し、ヘッダを読み、レコード r を構築し、同じ処理を新しい (より処理の進んだ) 途中結果 f r accu とともにレコードの末尾から行います。この処理はヘッダが無くなるまで、つまりアーカイブの終端に達するまで繰り返されます。
fold 関数の使用例として、レコードの名前を保存すること無く表示する処理を示します:
コマンド readtar a f はアーカイブの中のファイル f を探索し、もしそれが通常ファイルならばその内容を表示します。f がアーカイブ内のファイル g に対するハードリンクであれば、アーカイブの中では別になっていたとしても本当は二つのファイルは同一なので、そのリンクをたどって g の内容を表示します。g と f のどちらがリンクでどちらがリンク先であるかはアーカイブが作られるときにどちらが先に探索されたかのみに依存します。ここではシンボリックリンクを追うことはしません。
ハードリンクの解決は以下の相互再帰関数によって行われます:
find_regular 関数はレコード r に対応する通常ファイルを探します。r が通常ファイルならば r を返します。r がハードリンクならば find_file 関数を使ってリンクの指すファイルをアーカイブにすでに保存されているレコード list の中から探します。それ以外の場合は関数は失敗します。
レコードが見つかった場合はその内容を表示します。ディスクリプタをレコードの開始地点に移動させた後は file_copy とよく似た処理になります。
これらの関数を組み合わせれば完成です:
まずターゲットのファイル名が見つかるまでアーカイブのレコード (内容は除く) を読みます。その後 find_regular 関数で実際にそのファイルの内容を含んでいるレコードを探します。この二回目の逆順の探索はアーカイブが矛盾なく作られている限り成功します。しかし一回目の探索はファイルがアーカイブに存在しない場合に失敗するので、処理が失敗した場合でも二つのエラーを区別するようになっています。
readtar コマンドを実装したメイン関数は以下のようになります:
untar a がアーカイブ a の全てのファイル (スペシャルファイルを除く) を抽出し新しいディレクトリとして作成するようなコマンド untar を作成してください。ファイルについての情報 (所有者、権限) は可能ならばアーカイブのものを復元してください。
ファイル階層は untar コマンドが実行されたディレクトリに再構築されるべきです。コマンドが現在のワーキングディレクトリのサブディレクトリではない場所に書き込むことは許されません。アーカイブにレコードが無いディレクトリはユーザのデフォルト権限で作られるようにしてください。
解答
open に対する O_CREAT を実装していないためです。string ではなく bytes となります。write システムコールを繰り返します — セクション 5.7 参照。しかしこの制限はシステムのキャッシュサイズよりも大きいので無視できます。tar フォーマットの拡張などの例外的なケースをエンコードするための値も取ります。

